
이 글의 원문은 https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_ml/py_kmeans/py_kmeans_understanding/py_kmeans_understanding.html 입니다.
이 글은 K-Means 클러스터링에 대한 개념을 예를 통해 설명합니다.
티셔츠를 만다는 어떤 회사가 있다고 합시다. 이 회사는 새로운 티셔츠를 만들어 시장에 뿌리려고 합니다. 분명이 이 회사는 모든 사람들이 만족하는 다양한 티셔츠 사이즈를 생산해야 합니다. 그래서 이 회사는 사람들의 키와 몸무게의 데이터를 수집해서 아래처럼 그래프로 표현 했습니다.
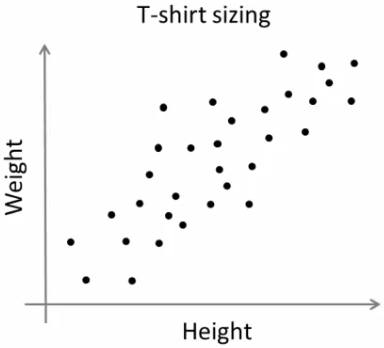
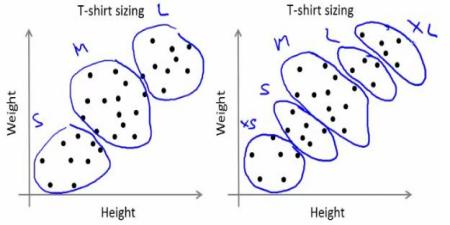
회사는 모든 사이즈에 대한 티셔츠를 만들 수는 없습니다. 대신에 작은 사이즈, 중간 사이즈, 큰 사이즈와 같이 3가지 사이즈를 만들고 모든 사람이 이 셋 중에 하나를 골라 만족하기를 기대합니다. 사람들을 이 3개의 그룹으로 나누는 것은 K-Means 클러스터링을 통해 가능하며, 이 알고리즘은 모든 사람들이 만족할 수 있는 최적의 3가지 사이즈를 산출해 낼 것입니다. 3가지로 부족하다면 4개로 그룹을 나눌 것이고.. 계속 만족할 만한 개수의 그룹으로 늘려나갈 수 있습니다. 아래 그럼처럼요.
자, 이제 이 K-Means 클러스터링의 알고리즘을 알아 봅시다. 그림을 통해 단계별로 설명하겠습니다.
아래와 같은 데이터셋을 살펴봅시다. 이 데이터셋을 앞서 언급한 티셔츠 데이터라고 할 수 있습니다. 이 데이터를 2개의 그룹으로 군집화(Clustering)해 봅시다.
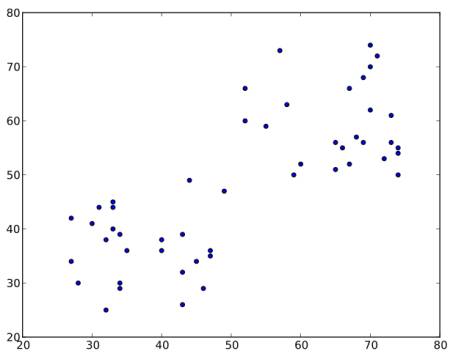
1단계
무작위로 2개의 중심점을 선택합니다. 이 중심점은 C1과 C2라고 합시다. (그냥 데이터 셋중 2개를 잡아서 그 2개가 C1, C2라고 해도 됩니다)
2단계
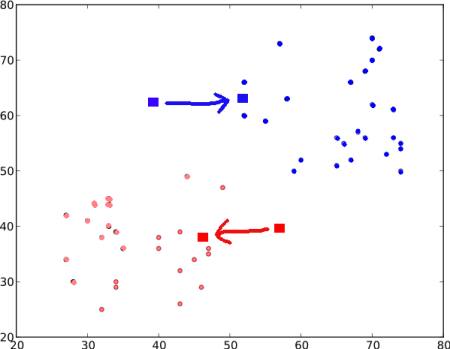
데이터셋을 구성하는 각각의 모든 포인트와 C1, C2 사이의 거리를 계산합니다. 만약 해당 포인트(테스트 데이터)가 C1에 더 가깝다면, 그 포인트에 ‘0’이라는 라벨을 붙입니다. 만약 C2에 더 가깝다면 ‘1’이라는 라벨을 붙이구요. (더 많은 중심점이 있다면 ‘2’, ‘3’ 등등이 되겠죠) 우리의 경우, ‘0’ 라벨은 빨간색으로, ‘1’ 라벨은 파란색으로 표시했습니다. 이 단계를 통해 아래와 같은 이미지를 얻을 수 있습니다.
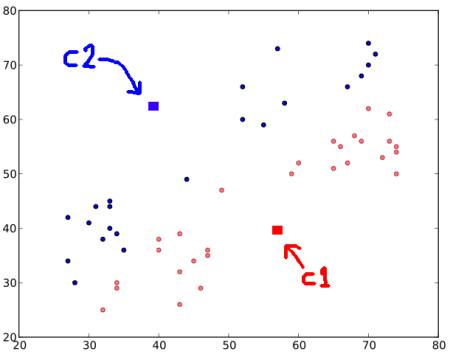
3단계
파란색 포인트 전체와 빨간색 포인트 전체에 대한 각각의 평균을 계산하고 이 평균을 새로운 중심점으로 갱신합니다. 즉 C1과 C2는 새롭게 계산된 중심점으로 이동되겠죠. 그리고 2단계를 다시 수행합니다. 그럼 다음과 같은 결과가 얻어집니다.
2단계와 3단계를 반복하는데, 중심점 C1과 C2가 더 이상 변경되지 않을 때까지 반복합니다. (또는 반복 회수의 제한을 두던지.. 중심점의 변경시 이동 거리에 대한 기준 등을 만족할때까지 반복할 수도 있습니다.) 반복이 멈추게 되면, 중심점과 이들 중심점과 연관된 포인트 간의 거리의 합이 최소가 됩니다. 간단이 말해, ![]() 와
와 ![]() 사이의 거리합이 최소입니다.
사이의 거리합이 최소입니다.
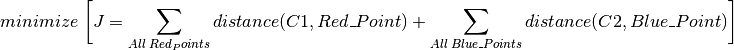
최종 결과는 아래와 같게 됩니다.
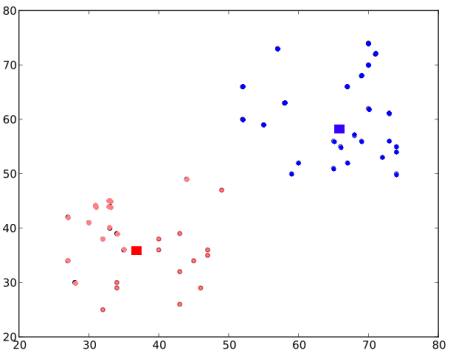
바로 이것이 K-Means 클러스터링에 대한 직관적인 이해이며, K-Means의 최상위 개념입니다. 여기에 다양한 변종과 응용이 추가됩니다. 예를들어 초기 중심점을 어떻게 결정하여 알고리즘의 속도를 향상시킬까 하는 등의 고민이 필요합니다.