
이 글의 원문은 https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_feature2d/py_matcher/py_matcher.html 입니다.
이제 두 개의 이미지에서 동일한 특징점을 찾아 매칭해 주는 내용을 살펴 보겠습니다. OpenCV에서는 이런 특징점 매칭을 Brute-Force 매칭이라고 하는데.. 이는 하나의 이미지에서 발견한 특징점을 다른 또 하나의 이미지의 모든 특징점과 비교해 가장 유사한 것이 동일한 특징점이라고 판별하는.. 단순하지만 다소 효율적이지 못한 방식이기 때문입니다.
Brute-Force 매칭을 위한, 즉 BF Matcher는 cv2.BFMatcher 함수를 통해 생성합니다. 이 함수는 2개의 선택적 인자를 받는데, 첫번째는 normType이며 거리 측정 방식을 지정합니다. 기본적으로는 cv2.NORM_L2이며 cv2.NORM_L1과 함께 키포인트와 특징점 기술자를 연산 방식인 SIFT, SURF에 좋습니다. ORB와 BRIEF, BRISK와 같은 2진 문자열 기반의 방식에서는 cv2.NORM_HAMMING가 사용되어져야 합니다. 만약 ORB가 VTA_K == 3 또는 4일 때, cv2.NORMHAMMING2가 사용되어져야 합니다. 두번재 인자는 crossCheck라는 Boolean 타입의 인자입니다. 기본값은 false이며 만약 True로 지정하면 A라는 이미지의 어떤 하나의 특징점을 B라는 이미지의 모든 특징점과 비교하는 것에서 끝나지 않고, 다시 B라는 이미지에서 찾은 가장 유사한 특징점을 A라는 모든 특징점과 비교하여 그 결과가 같은지를 검사하라는 옵션입니다. 보다 정확한 동일 특징점을 추출하고자 한다면 True를 지정하면 됩니다.
일반 BF Matcher 객체가 생성되면 match()와 knnMatch()라는 함수를 사용합니다. 첫번째는 가장 좋은 매칭 결과를 반환하고, 두번째 함수는 사용자가 지정한 k개의 가장 좋은 매칭 결과를 반환합니다. 특징점을 표시하는 cv2.drawKeypoints()와 같이, 2개의 이미지 간의 동일 특징점을 선으로 연결에 표시해 주는 cv2.drawMatches() 함수와 cv2.drawMatchesKnn() 함수가 있습니다.
이제 실제 예제 코드를 살펴 보겠습니다. 첫번째는 ORB 기술자를 사용한 특징점 비교, 두번째는 SIFT 기술자를 사용한 특징점 비교, 끝으로 세번째는 FLANN 방식의 특징점 비교입니다.
먼저 첫번째로 ORB 기술자를 사용한 특징점 비교에 대한 예제입니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('./data/harleyQuinnA.jpg',0)
img2 = cv2.imread('./data/harleyQuinnB.jpg',0)
orb = cv2.ORB_create()
kp1, des1 = orb.detectAndCompute(img1,None)
kp2, des2 = orb.detectAndCompute(img2,None)
bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)
matches = bf.match(des1,des2)
matches = sorted(matches, key = lambda x:x.distance)
img3 = cv2.drawMatches(img1,kp1,img2,kp2,matches[:10],None,flags=2)
plt.imshow(img3),plt.show()
결과는 다음과 같았습니다. (아래 결과는 상당이 부정확한데, 다른 사이트의 실행을 보면 이와 상반된 결과를 볼 수 있습니다. 설치된 OpenCV의 버전에 따른 영향이 아닌가 생각됩니다)

13번 코드에서 BF Matcher 객체를 생성하고 있는데, ORB를 사용하므로 cv2.NORM_HAMMING를 지정하고 있습니다. 17번에서는 매칭 결과에서 거리에 따로 오름차순으로 정렬하였습니다. 거리값이 작을수록 더 좋은 결과입니다. 19번 코드에서는 이렇게 정렬된 것 중 10개만을 화면에 표시하고 있습니다.
BF Matcher의 match() 함수의 결과는 DMatch 객체의 리스트입니다. 이 객체는 다음과 같은 속성을 갖습니다.
- DMatch.distance : 기술자(Descriptor) 간의 거리로써, 작을수록 더 좋은 결과임
- DMatch.trainIdx : 연습 기술자 리스트에 저장된 인덱스(위 예제에서 img1에서 추출한 기술자가 연습 기술자임)
- DMatch.queryIdx : 조회 기술자 리스트에 저장된 인덱스(위 예제에서 img2에서 추출한 기술자가 조회 기술자임)
- DMatch.imgIdx : 연습 이미지의 인덱스
두번째 예제는 SIFT 기술자를 이용한 특징점 비교입니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('./data/harleyQuinnA.jpg',0)
img2 = cv2.imread('./data/harleyQuinnB.jpg',0)
sift = cv2.xfeatures2d.SIFT_create()
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
bf = cv2.BFMatcher()
matches = bf.knnMatch(des1,des2, k=2)
good = []
for m,n in matches:
if m.distance < 0.3*n.distance:
good.append([m])
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,good,None,flags=2)
plt.imshow(img3),plt.show()
결과는 아래와 같습니다.
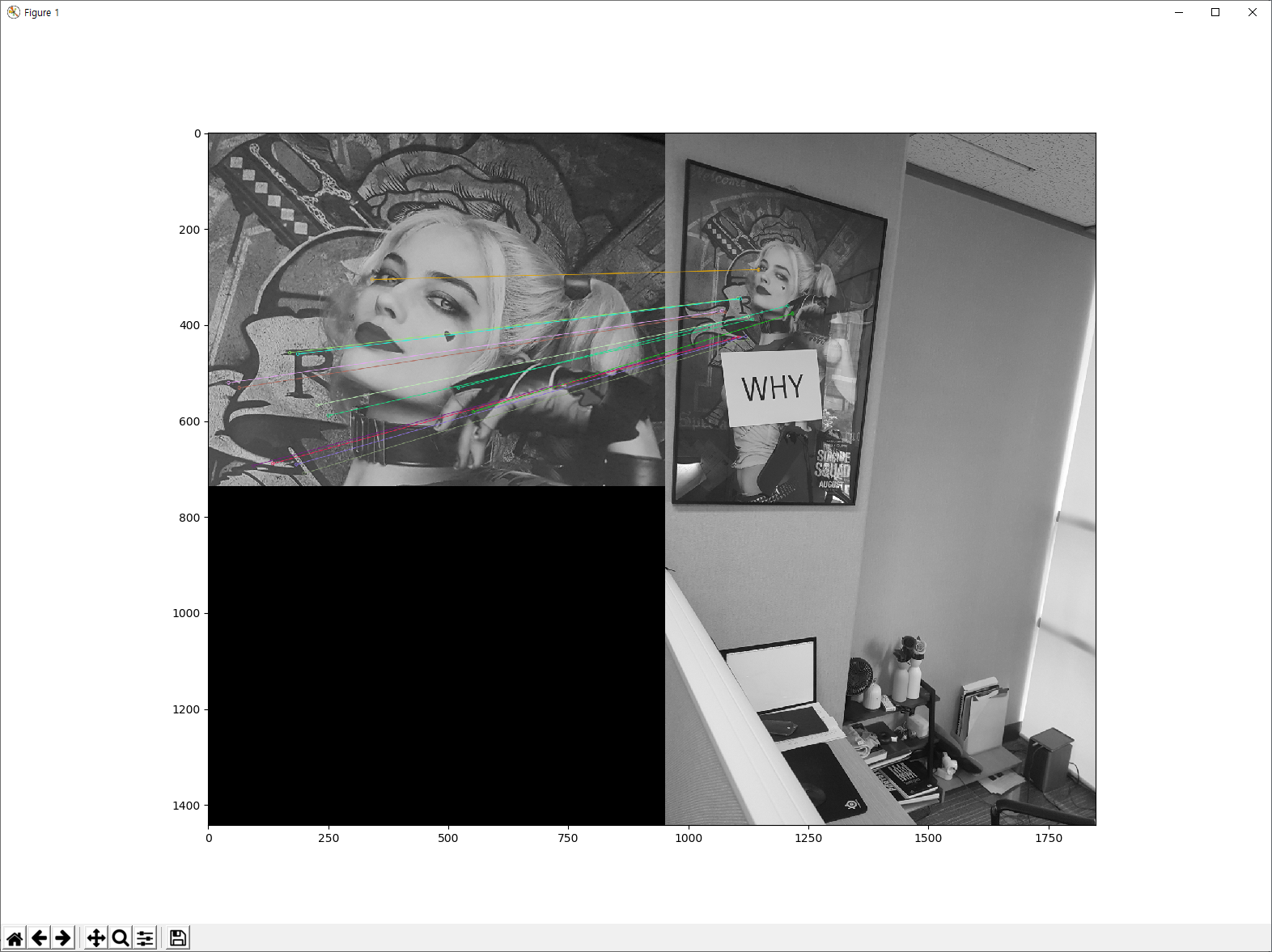
마지막 예제는 FLANN 입니다. FLANN은 Fast Library for Approximate Nearest Neighbors의 약자입니다. 대용량의 데이터셋과 고차원 특징점에 있어서 속도면에 최적화 되어 있습니다. 이는 앞서 살펴본 BF Matcher 방식보다 좀더 빠릅니다.
FLANN 기반 Matcher를 위해, 알고리즘 수행을 위한 2개의 dictionary가 필요합니다. 첫번째는 IndexParams 인데, SIFT나 SURF 등의 경우 아래처럼 생성할 수 있습니다.
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
ORB의 경우에는 다음처럼 생성됩니다.
index_params= dict(algorithm = FLANN_INDEX_LSH,
table_number = 6, # 12
key_size = 12, # 20
multi_probe_level = 1) #2
두번째 dictionary는 SearchParams이며 다음처럼 생성됩니다. 정밀도를 높이기 위해 더 높은 checks 갑을 지정할 수 있지만 시간이 더 소요 됩니다.
search_params = dict(checks=100)
전체 예제 코드는 아래와 같습니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img1 = cv2.imread('./data/harleyQuinnA.jpg',0)
img2 = cv2.imread('./data/harleyQuinnB.jpg',0)
# Initiate SIFT detector
sift = cv2.xfeatures2d.SIFT_create()
# find the keypoints and descriptors with SIFT
kp1, des1 = sift.detectAndCompute(img1,None)
kp2, des2 = sift.detectAndCompute(img2,None)
# FLANN parameters
FLANN_INDEX_KDTREE = 0
index_params = dict(algorithm = FLANN_INDEX_KDTREE, trees = 5)
search_params = dict(checks=50) # or pass empty dictionary
flann = cv2.FlannBasedMatcher(index_params,search_params)
matches = flann.knnMatch(des1,des2,k=2)
# Need to draw only good matches, so create a mask
matchesMask = [[0,0] for i in range(len(matches))]
# ratio test as per Lowe's paper
for i,(m,n) in enumerate(matches):
if m.distance < 0.3*n.distance:
matchesMask[i]=[1,0]
draw_params = dict(matchColor = (0,255,0),
singlePointColor = (255,0,0),
matchesMask = matchesMask,
flags = 0)
img3 = cv2.drawMatchesKnn(img1,kp1,img2,kp2,matches,None,**draw_params)
plt.imshow(img3,),plt.show()
결과는 아래와 같습니다.

안녕하세요 한글로 잘 설명 해주셔서 감사합니다. 다만 초보자 분들이 글을 읽다가 오류에 부딪힐까 한가지 첨언 하자면, ORB의 FLANN 적용 단계에서 index params 직전에 FLANN_INDEX_LSH가 변수로 선언이 되었다는 내용이 빠졌네요. FLANN_INDEX_LSH=6 이어야지 작동합니다. ㅎㅎ 즉 현재 상태로 사용하려면 변수선언을 먼저해주거나 algorithm = 6 이렇게 대입해줘야합니다.
안녕하세요, 좋은 글 잘 읽었습니다.
실행까지 모두 완벽하게 되네요. 감사합니다.
다름이 아니라 한 가지 질문이 있어 글을 남깁니다.
특징점 매칭이 완료 후 출력한 이미지에서 ‘이미지 간의 차이 정도 또는 유사도’를 수치화 할 수 있는 방법 또한 있을까요?
안녕하세요, 김형준입니다.
해당 글은 번역한 글로, 번역 이상의 내용은 저도 잘모릅니다..