
밀도맵에 대해 고민을 본격적으로 해보고 있는데, 먼저 내가 알고 있는 밀도맵이라는 개념은 틀린 것임을 알았다. 밀도맵이 아닌 밀도분석에 의한 결과라고 해야 옳겠다. 밀도맵은 아래처럼 지도의 영역을 통계수치값에 따라 다른 색상으로 구분해 놓은 맵을 말한다.
밀도 분석에 대해 관심을 가지게 된 이유는 이 밀도 분석을 구현해보고자 함이다. 그러기 위해서는 정확히 밀도 분석이라는 것이 무엇인가 부터 정확히 파악해야 어떤식으로 구현을 할지 알 수 있을 것이기 때문이다.
밀도 분석은 어떤 지점의 현상에 대한 측정된 수량(예를들어 인구수)을 지도 전체에 걸쳐 측정된 수량을 재분배를 해주는 것이다. 재분배는 지도를 일정한 간격의 Grid의 Cell의 값으로써 이루어진다. 아래의 그림이 포인트에 대한 밀도분석의 결과를 나타낸 화면이다.
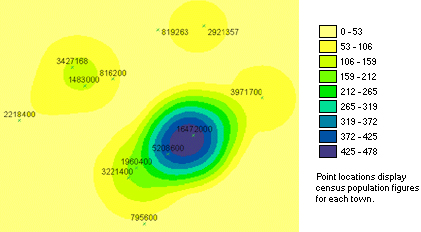
이런 밀도 분석의 목적에 대해서 알아보자. 밀도 분석에 의한 결과를 Density Surface, 즉 밀도폴리곤이라고 하면… 밀도폴리곤은 측정값을 속성으로 하는 포인트나 라인 피쳐가 어디에 집중되었는가를 보여준다. 예를들어서 하나의 포인트가 어떤 마을을 의미하고 그 포인트 속성으로 마을의 전체 주민수를 나타낸다고 해보자. 여기서 우리는 이 주민수 포인트 데이터로부터 지도 전체에 걸친 주민의 분포수를 알고자 하는 것이다. 이 주민의 분포수를 얻는 방법이 바로 밀도 계산인데, 지도 전체에 걸친 인구의 예측 분포를 보여주는 밀도 폴리곤을 생성할 수 있는 것이 바로 밀도 분석, 밀도 계산이다.
여기서 중요한 것은 밀도 폴리곤은 벡터가 아닌 라스터라는 점이다. 밀도 분석에 의해 라스터를 구성하는 각 Cell에 측정된 값들이 계산되어져 입력되는데, 모든 Cell의 값들을 합한값과 입력 데이터로써의 벡터 데이터의 측정값들의 합은 같다.
밀도 분석을 위해 필요한 입력값은 무엇일까? 앞의 설명으로부터 유추가 가능한데.. 한번 정리를 해보면 아래와 같다.
- 측정값이 들어가 있는 포인트나 폴리라인 벡터 데이터(여기서는 포인트에 관심을 둠)
- 측값값이 저장된 속성 데이터에 대한 필드명
- 밀도 분석 방법(Kernel과 Simple 방법이 있음)
- 검색 반경
- 셀의 크기
위의 지식을 기반으로 밀도 분석을 구현해 그 결과를 제시해 보겠다.
먼저 입력 데이터는 아래와 같다. 직관적으로 결과를 보이기 위해 하나의 포인트는 1의 값을 갖는다고 했다.
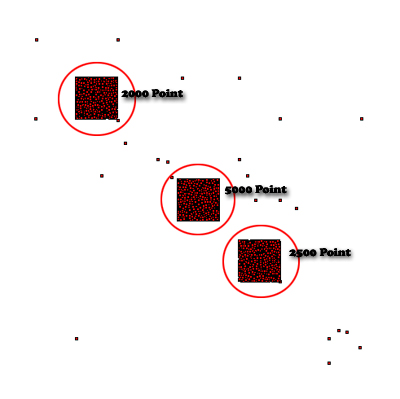
대략 9500개의 포인트를 사용했다. 화면의 가운데 부분에 5000개의 포인트를 밀집 시켰고 이를 중심으로 2000개의 포인트와 2500개의 포인트를 밀집시켰다. 직접 구현한 밀도 분석은 아래와 같다. 처음 이미지는 Simple 방법이고 두번째는 Kernel 방법이다.


Kernel 방법이 훨씬 정확한 결과를 제시하고 있다는 것을 알 수 있다. 아직은 속도나 퀄러티(밀도의 단계가 10단계로 표출되어야하나 그 이하로 표출(위의 경우 9단계)되는 문제가 발생하는 문제가 있다.
기회가 닿는다면 밀도분석에 대한 Simple 방법과 Kernel 방법에 대한 구현 로직에 대해 설명해 보도록 하겠다.