
이 글은 동적 웹 페이지에서 주소 데이터를 취득하기 위한 파이썬 코드를 설명합니다.
동적 페이지라함은 웹 페이지에서 사용자의 클릭 등과 같은 조작을 통해 AJAX 호출이 발생하여 그 결과가 페이지의 일부분에 반영되어 변경되는 것을 의미합니다. 예를 들어 아래의 커피빈 페이지에서 매장 정보를 확인하기 위해 사용자는 다음과 같은 절차를 통해 매장의 이름과 주소 그리고 전화번호를 확인할 수 있습니다.
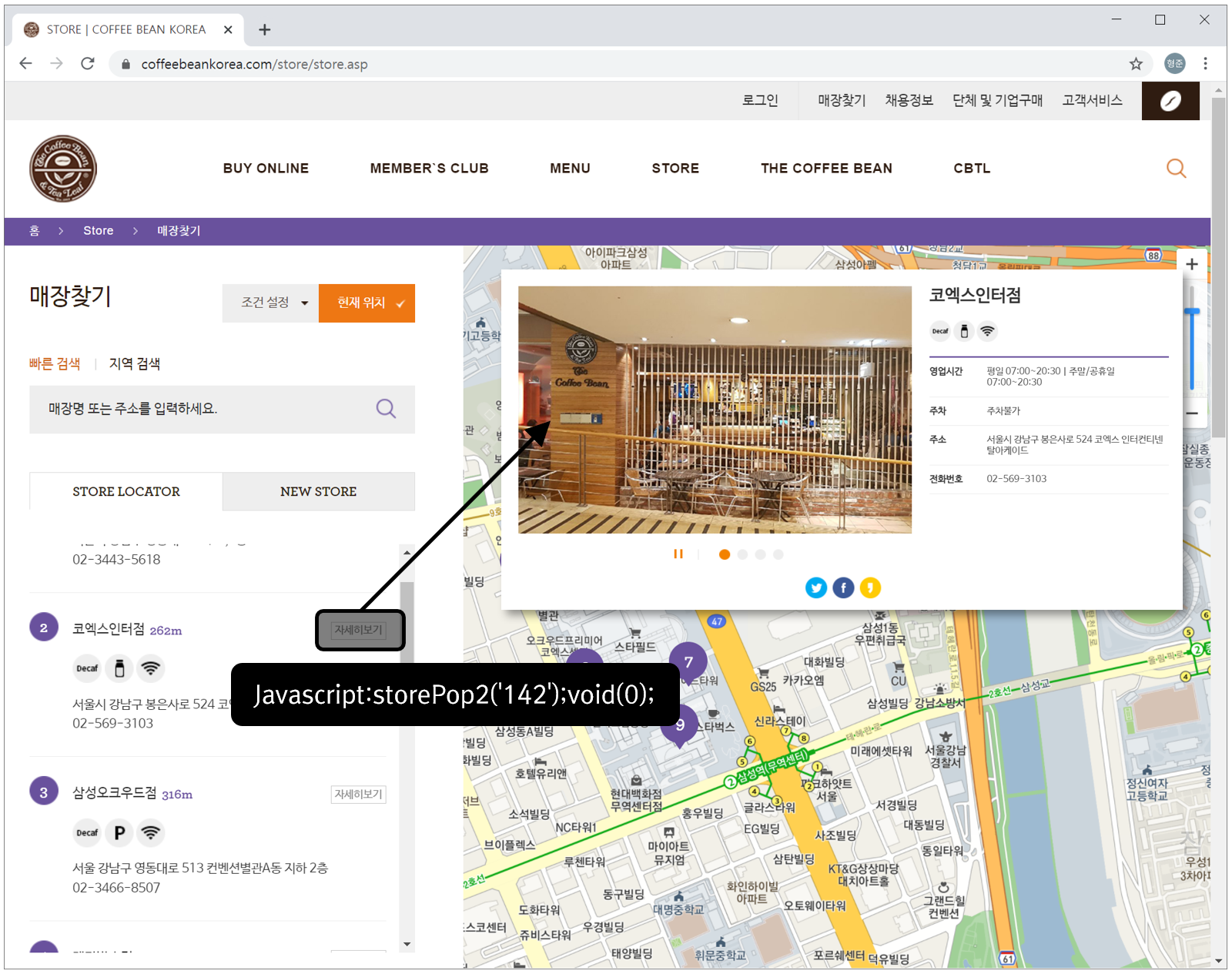
위의 그림을 글로 설명하면, 먼저 사용자는 정보를 파악할 매장에 대한 “자세히 보기” 버튼을 클릭하면 웹브라우저가 연결된 javascript 코드를 실행하여 해당 매장의 상세 정보가 동일한 페이지에 동적으로 표시됩니다.
이러한 사용자의 조작을 자동화하기 위해서는 Selenium 라이브러리를 사용합니다. 이 라이브러리는 웹 브라우저를 코드를 통해 제어하기 위한 라이브러리이며, 내부적으로는 Web Driver라는 프로그램을 사용합니다. 아울러 HTML 페이지를 해석하여 원하는 정보를 추출할 수 있는 BeautifulSoup 라이브러리도 필요합니다.
BeautifulSoup는 다음과 같은 pip 명령을 통해 설치할 수 있습니다.
pip install beautifulsoup4
Selenium은 다음과 같은 pip 명령으로 설치할 수 있습니다.
pip install selenium
언급했듯이 selenium은 Web Driver가 필요한데 Windows의 Chrome에 대한 드라이버는 현재 시점에서 다음 url을 통해 다운로드 받을 수 있습니다.
https://chromedriver.storage.googleapis.com/index.html?path=88.0.4324.96/
다운로드 받은 파일명은 chromedriver_win32.zip이며 압축을 풀면 chromedriver.exe가 생성됩니다.
이제 준비가 완료되었으므로 코드를 살펴보겠습니다. 먼저 필요한 라이브러리를 import 합니다.
from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions from bs4 import BeautifulSoup import pandas as pd
pandas는 크롤링한 데이터를 csv 파일로 저장하기 위해 사용됩니다.
다음으로 Web Driver에 대한 객체를 생성합니다.
wd = webdriver.Chrome('./WebDriver/chromedriver.exe')
이제 다음의 코드로 사용자의 클릭을 통해 호출되는 자바스크립트 함수를 Web Driver를 통해 자동화합니다.
result = []
for i in range(1, 100):
try:
wd.get('https://www.coffeebeankorea.com/store/store.asp')
wd.execute_script('storePop2(%d)' %i)
element = WebDriverWait(wd, 2).until(
expected_conditions.presence_of_element_located((By.CLASS_NAME, "store_table")))
html = wd.page_source
soup = BeautifulSoup(html, 'html.parser')
store_name = soup.select('.store_txt > h2')[0].string
store_info = soup.select('table.store_table > tbody > tr > td')
store_address = list(store_info[2])[0]
store_phone = store_info[3].string
result.append([store_name, store_address, store_phone])
print(f'{i} : {store_name} {store_address} {store_phone}')
except:
print(f'{i} : not exist')
continue
wd.quit()
df = pd.DataFrame(result, columns = ('name', 'address', 'phone'))
df.to_csv('./CoffeeBean.csv', encoding='utf-8', mode='w', index=False)
print('Completed..')
위의 코드는 1-99번까지의 인자값에 대한 자바스크립트 함수(storePop2)를 호출하며 호출된 결과인 html 문자열에서 필요한 정보를 추출하여 CSV 파일로 저장하는 코드입니다. 실행 결과로 저장되는 CSV 파일의 일부 내용은 다음과 같습니다.
name,address,phone
학동역 DT점,서울시 강남구 학동로 211 1층 ,02-3444-9973
수서점,서울시 강남구 광평로 280 수서동 724호 ,02-3412-2326
차병원점,서울시 강남구 논현로 566 강남차병원1층 ,02-538-7615
강남대로점,서울시 서초구 강남대로 369 1층 ,02-588-5778
메가박스점,서울 강남구 삼성동 159 코엑스몰 지하2층 ,02-6002-3320
.
.
.
이렇게 만들어진 파일을 통해 실제 공간 좌표로 변환하기 위한 지오코딩 툴은 Geocoder-Xr를 사용하시는 것을 추천드립니다.
끝으로 이 글은 “데이터 과학 기반의 파이썬 빅데이터 분석(저자 이지영)”이라는 서적을 원저자의 허락 하에 참조하여 작성하였습니다.

이 책은 빅데이터에 대한 깊이 있는 이해를 돕는 이론으로 시작해 빅데이터를 수집하는 구체적인 방법과 이렇게 수집된 데이터를 파이썬 언어를 이용하여 분석하고 분석 결과를 효과적으로 시각화하는 방법을 구체적으로 설명하고 있습니다. 크롤링에 대한 좋은 예제를 이 블로그를 통해 공개할 수 있도록 허락해주신 이 책의 저자이신 이지영님에게 감사드립니다.