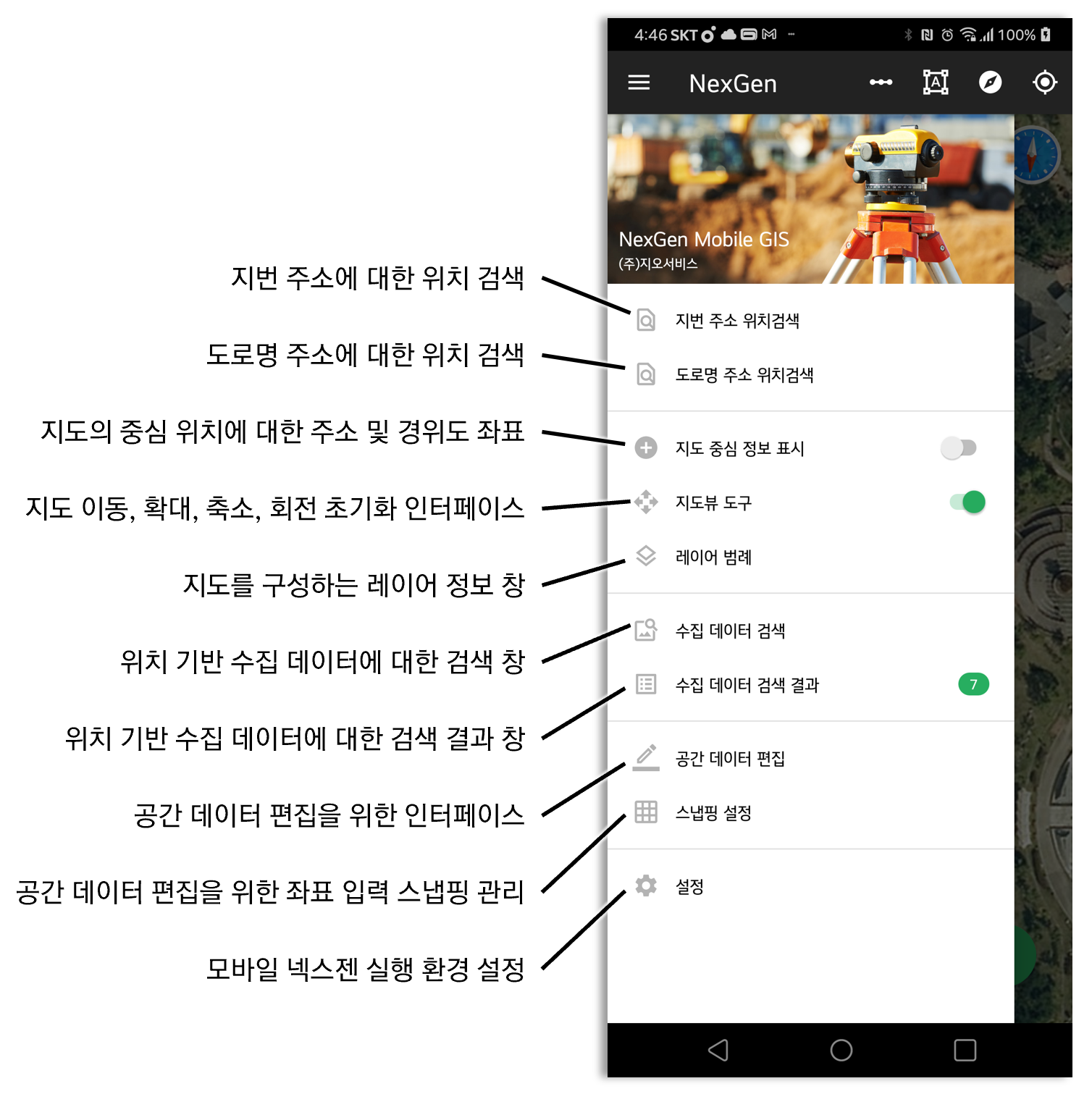
Drawer Menu는 안드로이드의 표준화된 메뉴입니다. 이 UI는 단순히 메뉴로써의 기능 뿐만이 아니라 다양한 정보를 사용자에게 제공할 수 있습니다. 이를 위해 Drawable의 특정 메뉴 항목의 우측에 커스텀 뷰를 달게 되면, 이 커스텀 뷰의 내용을 변경함으로써 어떤 정보를 사용자에게 전달할 수 있게 됩니다. 이 글은 이처럼 Drawable의 특정 메뉴 항목에 커스텀 뷰를 추가하는 코드를 정리합니다.
Drawer Menu를 추가하기 위해서는 Activity의 Layout에서 기본적으로 com.google.android.material.navigation.NavigationView를 사용하게 됩니다. 이를 NavigationView를 통해 메뉴의 각 항목에 접근할 수 있고, 접근된 메뉴에 원하는 View를 지정할 수 있게 됩니다. 아래 코드처럼요.
navigationView = findViewById<NavigationView>(R.id.main_navigation_view)
...
navigationView.getMenu().getItem(4).setActionView(R.layout.drawer_menu_item_collecting_data_searched_items_count)
위의 코드는 5번째 메뉴에 대한 커스텀 뷰를 R.layout.drawer_menu_item_collecting_data_searched_items_count으로 지정하고 있습니다. R.layout.drawer_menu_item_collecting_data_searched_items_count에 대한 코드는 다음과 같습니다.
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:gravity="center_vertical"
android:orientation="vertical" >
<TextView
android:background="@drawable/rounding_box"
android:id="@+id/tvResultItemCount"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:textColor="#ffffff"
android:textSize="@dimen/very_small_text_size"
android:paddingVertical="2dp"
android:paddingHorizontal="10dp"
android:text="0" />
</LinearLayout>
위의 뷰를 좀더 시각적으로 안정감 있도록 배경을 rounding_box라는 Drawable로 지정하였는데요. rounding_box 코드는 다음과 같습니다.
<shape xmlns:android="http://schemas.android.com/apk/res/android">
<solid android:color="@color/uiColor" />
<padding
android:left="45px"
android:top="15px"
android:right="45px"
android:bottom="15px" />
<corners android:radius="30px" />
</shape>
앞서 언급했던 것처럼 Drawer Menu의 항목에 대한 커스텀 뷰의 내용을 변경함으로써 정보를 사용자에게 전달한다고 했는데, 커스텀 뷰를 변경하는 코드의 예는 다음과 같습니다.
navigationView.getMenu().getItem(4).actionView.findViewById<TextView>(R.id.tvResultItemCount).text = "999"