몇번을 사용해도 맨날 잊는다. 추후 다시 RecycleView를 사용할때 참조하기 위해 정리해 둔다.
먼저 레이아웃 요소로서 추가한다.
<androidx.recyclerview.widget.RecyclerView
android:id="@+id/rvCollectingData"
android:layout_width="match_parent"
android:layout_height="match_parent" />
RecycleView는 유사한 레이아웃을 갖는 내용만 다른 항목에 대한 리스트 UI인데, 먼저 항목을 구성하는 데이터 클래스 정의가 필요하다.
package geoservice.nexgen.collectingdata.datalistactivity
import geoservice.nexgen.collectingdata.DataCollectingDB
data class DataCollectingListItem(
val id: Int,
val link_id: Int,
val type: DataCollectingDB.Type,
val data: String,
val title: String,
val date: String
)
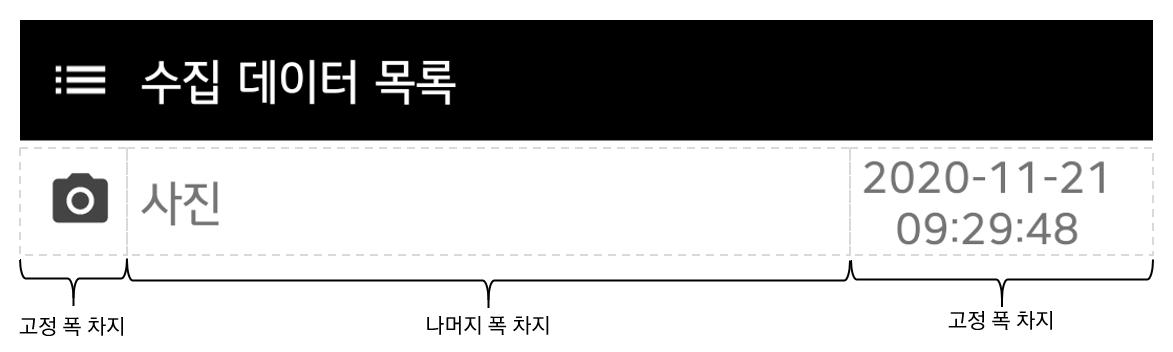
항목에 대한 레이아웃도 필요한데 다음과 같다. 파일명은 data_collection_list_recycler_view_item.xml로 지정한다.
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout xmlns:android="http://schemas.android.com/apk/res/android"
xmlns:app="http://schemas.android.com/apk/res-auto"
android:layout_width="match_parent"
android:layout_height="44dp"
android:paddingHorizontal="10dp"
android:gravity="center_vertical"
android:orientation="horizontal">
<ImageView
android:id="@+id/ivIcon"
android:src="@drawable/ic_layers_black"
android:layout_width="wrap_content"
android:layout_height="wrap_content"
app:tint="#444444" />
<TextView
android:textSize="@dimen/normal_text_size"
android:id="@+id/tvCaption"
android:layout_marginLeft="10dp"
android:layout_width="match_parent"
android:layout_weight="1"
android:layout_height="wrap_content" />
<TextView
android:textSize="@dimen/small_text_size"
android:id="@+id/tvDate"
android:layout_width="100dp"
android:textAlignment="center"
android:layout_height="wrap_content" />
</LinearLayout>
이제 위에서 정의한 코드와 레이아웃이 적용된 Adapter 클래스를 추가한다.
package geoservice.nexgen.collectingdata.datalistactivity
import android.view.LayoutInflater
import android.view.View
import android.view.ViewGroup
import android.widget.ImageView
import android.widget.TextView
import androidx.recyclerview.widget.RecyclerView
import geoservice.nexgen.R
import geoservice.nexgen.collectingdata.DataCollectingDB
class DataCollectingListRecyclerViewAdapter(val items: ArrayList<DataCollectingListItem>)
: RecyclerView.Adapter<RecyclerView.ViewHolder>() {
internal inner class ViewHolder(itemView: View) : RecyclerView.ViewHolder(itemView) {
val ivIcon = itemView.findViewById<ImageView>(R.id.ivIcon)
val tvCaption = itemView.findViewById<TextView>(R.id.tvCaption)
val tvDate = itemView.findViewById<TextView>(R.id.tvDate)
}
override fun onCreateViewHolder(viewGroup: ViewGroup, i: Int): RecyclerView.ViewHolder {
val view: View = LayoutInflater.from(viewGroup.context)
.inflate(R.layout.data_collection_list_recycler_view_item, viewGroup, false)
return ViewHolder(view)
}
override fun onBindViewHolder(viewHolder: RecyclerView.ViewHolder, i: Int) {
val holder = viewHolder as ViewHolder
val item = items[i]
when(item.type) {
DataCollectingDB.Type.FORM -> holder.ivIcon.setImageResource(R.drawable.ic_form_black)
DataCollectingDB.Type.MOVIE -> holder.ivIcon.setImageResource(R.drawable.ic_movie_black)
DataCollectingDB.Type.PHOTO -> holder.ivIcon.setImageResource(R.drawable.ic_photo_camera_black)
}
holder.tvCaption.text = item.title
holder.tvDate.text = item.date
}
override fun getItemCount(): Int {
return items.size
}
}
이제 Activity에서 RecycleView에 대한 설정 코드를 작성하는데, 먼저 레이아웃을 잡는다.
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
rvCollectingData.layoutManager = LinearLayoutManager(this)
}
다음은 RecycleView에 표시될 데이터 항목을 구성하고 Adapter로 지정하는 코드이다.
private fun setupCollectionDataRecycleView(id: Int) {
var items: ArrayList<DataCollectingListItem>? = null
val job = GlobalScope.launch(Dispatchers.IO) {
items = MainActivity.dataCollectingDB.getSubItems(id)
}
GlobalScope.launch(Dispatchers.Main) {
job.join()
items?.let {
rvCollectingData.adapter = DataCollectingListRecyclerViewAdapter(it)
}
}
}
좀더 이해를 돕고자, 위의 코드 중 MainActivity.dataCollectingDB.getSubItems 함수는 다음과 같다.
fun getSubItems(link_id: Int): ArrayList<DataCollectingListItem> {
val result = ArrayList<DataCollectingListItem>()
val sql = "SELECT id, type, data, title, date FROM sub_item WHERE link_id = $link_id"
Log.v("DIP2K", sql)
val stmt = db.prepare(sql)
while (stmt.step()) {
val id = stmt.column_int(0)
val type = stmt.column_string(1)
val data = stmt.column_string(2)
val title = stmt.column_string(3)
val date = stmt.column_string(4)
val item = DataCollectingListItem(id, link_id, Type.valueOf(type), data, title, date)
result.add(item)
}
return result
}