아래 평판에 원 모양의 Quad를 추가하기 위해서 어떻게 해야 할까…
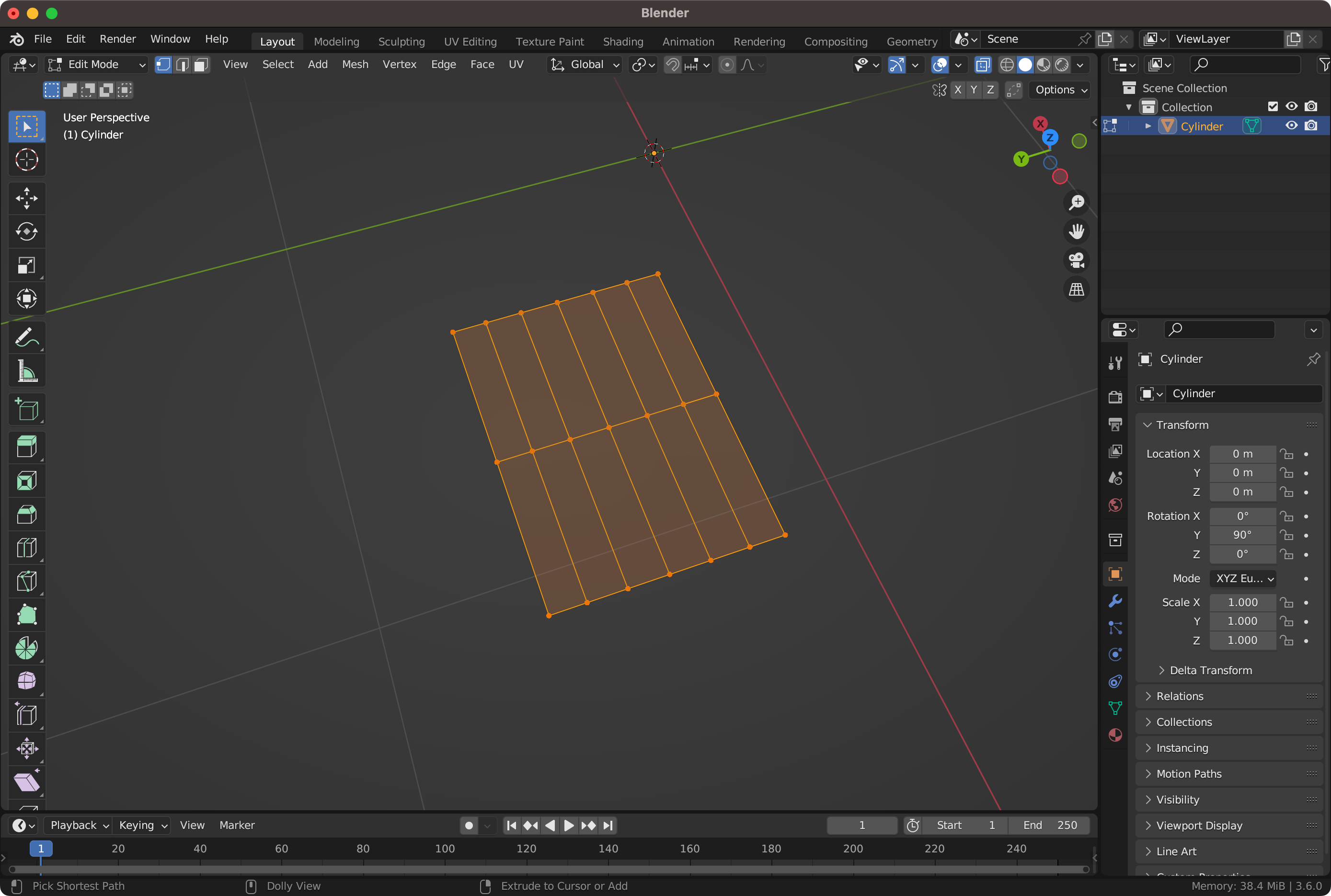
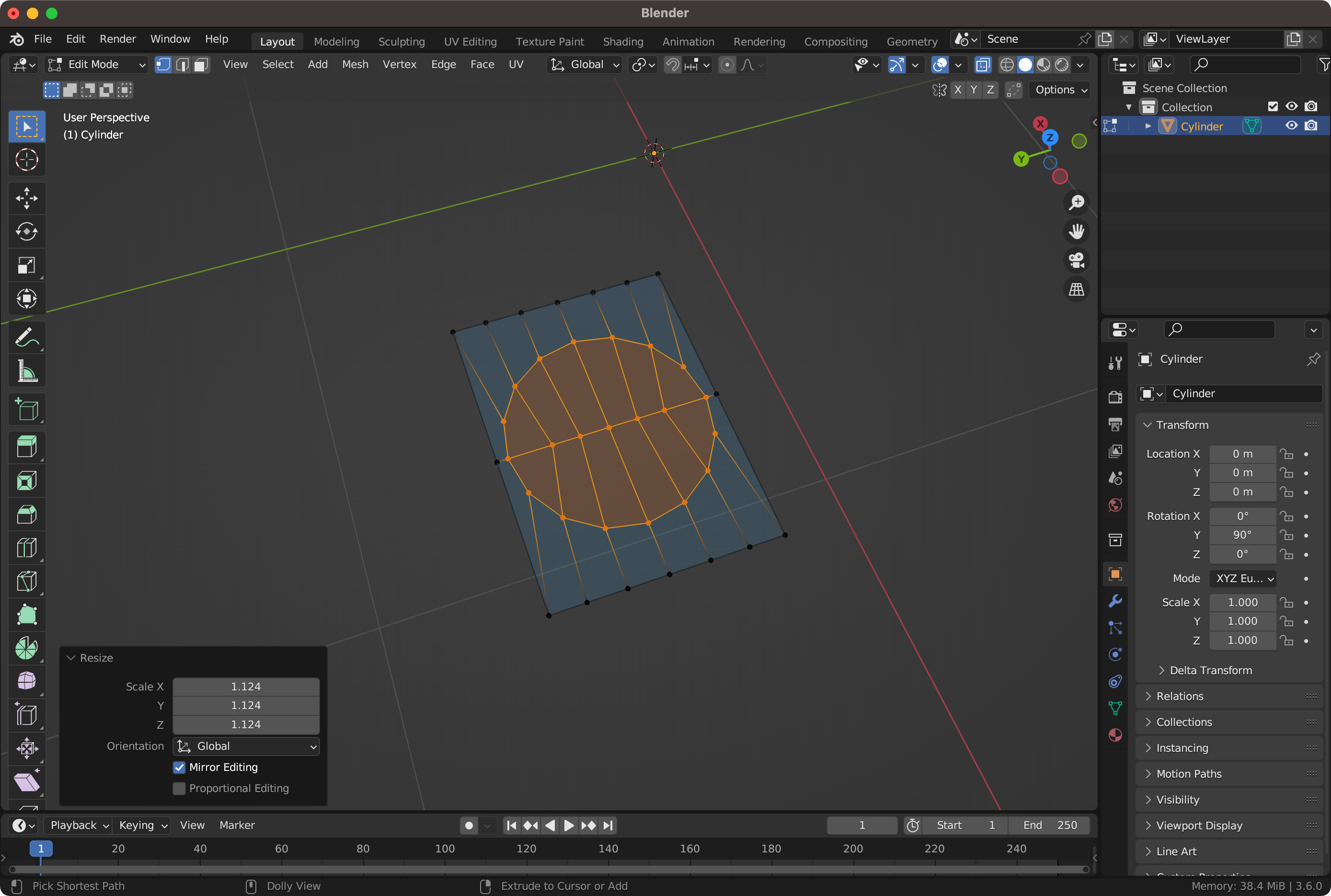
전체 면 선택하고 Inset Faces한 뒤 Loop Tools-Circle을 하면 쉽게 Quad로 구성된 결과를 얻을 수 있음.

공간정보시스템 / 3차원 시각화 / 딥러닝 기반 기술 연구소 @지오서비스(GEOSERVICE)
아래 평판에 원 모양의 Quad를 추가하기 위해서 어떻게 해야 할까…
전체 면 선택하고 Inset Faces한 뒤 Loop Tools-Circle을 하면 쉽게 Quad로 구성된 결과를 얻을 수 있음.
아래와 같은 N-Gon이 있는데 어떻게 해야할까 …
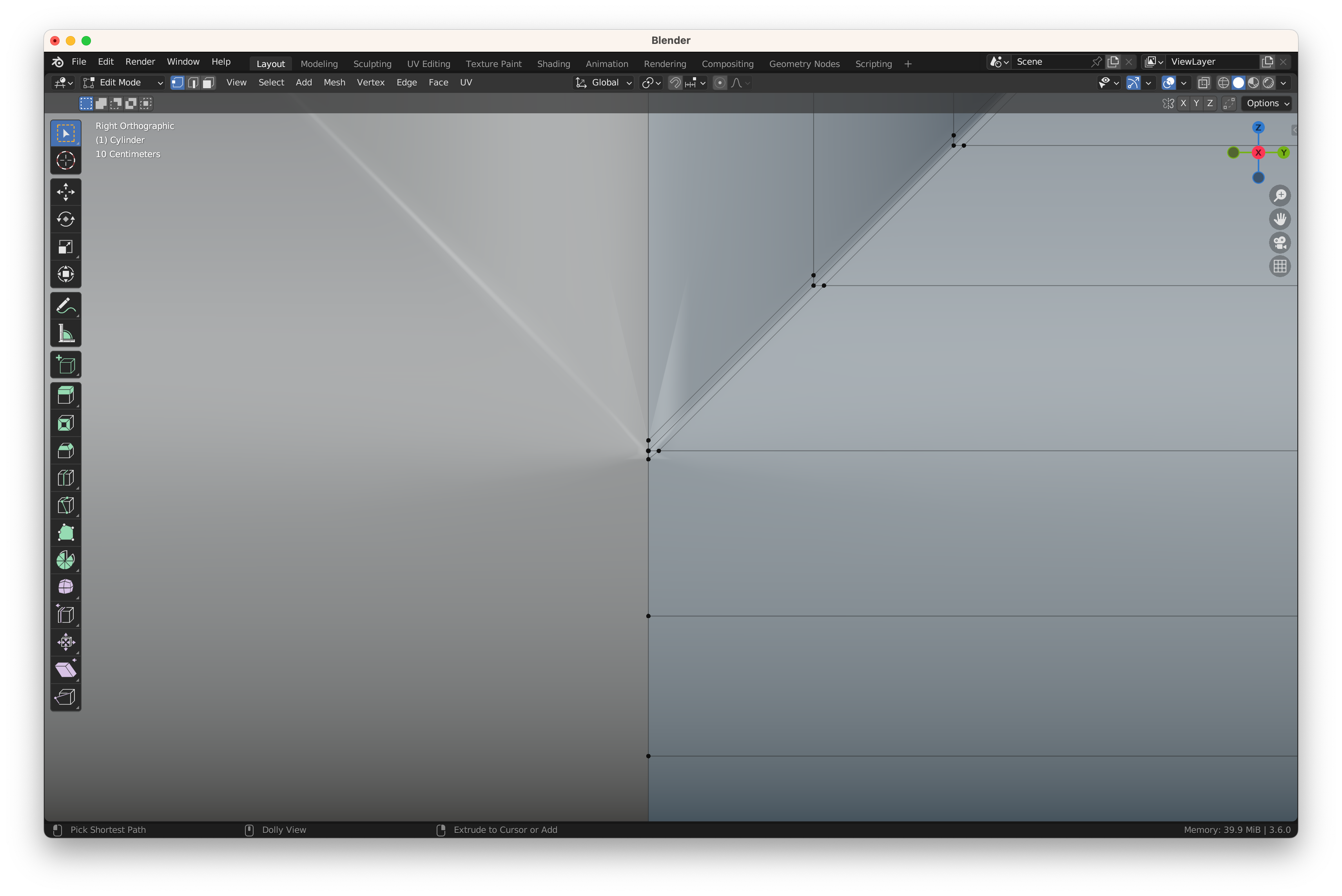
정점을 하나 위로 이동해서 Merge 하고 …
Knife 툴로 잘라주면 Quad 완성