OpenGL Setup for GLSL – Overview
원문: http://www.lighthouse3d.com/opengl/glsl/index.php?ogloverview
GLSL을 위한 OpenGL 설정이라는 이 섹션은 두개의 버텍스 쉐이더와 프레그먼트 쉐이더에 대해 들어봤다고 가정을 하고 진행되며 OpenGL 어플리케이션에서 이 쉐이더들을 사용기 위한 내용이다. 만약 아직까지 직접 쉐이더를 작성해보지 않았다면, 인터넷으로부터 쉐이더를 구할 많은 사이트가 있으니 참고하길 바란다. 참고 사이트는 http://www.3dshaders.com/home/가 있으며 쉐이더 개발을 위한 툴로는 Shader Designer와 RenderMonkey (원문에서는 링크가 깨져있으며 구글에서 검색해서 현재 사용가능한 사이트의 URL을 검색해보길 바란다)가 있고, 이 툴에는 매우 많은 쉐이더 예제가 있다.
OpenGL을 보면, 쉐이더 프로그램을 설정하는 것은 C 프로그램을 작성하는 흐름과 유사하다. 각 쉐이더는 C 모듈과 유사하며 이 모듈은 C언어에서 처럼 개별적으로 컴파일되어져야하고, 또 정확히 C에서처럼 프로그램에 링크되여야 한다.
ARB 확장들과 OpenGL이 이 섹션에서 사용된다. 만약에 OpenGL의 버전이 1.1 이상을 사용해 보지 않았거나 확장이 처음이라면, GLEW를 보길바란다. GLEW는 확장기능과 OpenGL 최신 함수 사용를 바로 사용할 수 있도록 해준다.
만약에 아직 OpenGL 2.0을 지원하지 않는다면, 확장을 이용해야 하는데, 필요한 확장은 아래와 같다.
- GL_ARB_fragment_shader
- GL_ARG vertex_shader
아래는 GLEW를 사용하는 GLUT 프로그램의 간단한 예제인데, 위의 두개의 확장을 사용할 수 있는지 검토하는 코드이다.
#include
#include ;
void main(int argc, char **argv) {
glutInit(&argc, argv);
...
glewInit();
if (GLEW_ARB_vertex_shader && GLEW_ARB_fragment_shader)
printf("Ready for GLSL\n");
else {
printf("Not totally ready :( \n");
exit(1);
}
setShaders();
glutMainLoop();
} OpenGL 2.0이 가능한지 검사하기 위해서 아래와 같은 코드를 사용한다.
#include
#include
void main(int argc, char **argv) {
glutInit(&argc, argv);
...
glewInit();
if (glewIsSupported("GL_VERSION_2_0"))
printf("Ready for OpenGL 2.0\n");
else {
printf("OpenGL 2.0 not supported\n");
exit(1);
}
setShaders();
glutMainLoop();
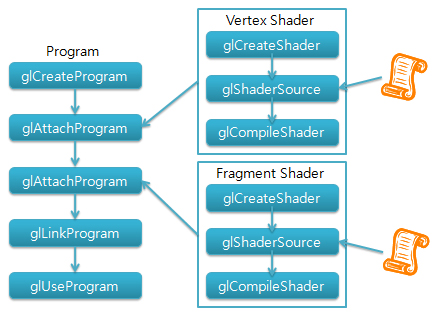
} 아래의 그림은 OpenGL 2.0의 함수로써 나타낸 쉐이더를 생성하는 단계를 나타내고 인데, 언급한 함수의 세부내용은 나중에 자세히 살펴보도록 하겠다.