
 오늘 PSP로 eBook을 볼 수 있는 방법을 검색해 보던 중에 웹 페이지를 볼 수 있다는 것을 알고 CodeProject에서 아티클 하나를 다운받아 전철에서 보았습니다. 저에겐 게임보다는 이렇게 PSP를 활용하는 것이 좋네요~
오늘 PSP로 eBook을 볼 수 있는 방법을 검색해 보던 중에 웹 페이지를 볼 수 있다는 것을 알고 CodeProject에서 아티클 하나를 다운받아 전철에서 보았습니다. 저에겐 게임보다는 이렇게 PSP를 활용하는 것이 좋네요~
[펌] 세계적 기업가들이 공유한 `富의 6단계 원칙’
원본 : http://news.media.daum.net/foreign/europe/200709/13/yonhap/v18126133.html?_right_TOPIC=R7
“버진그룹 회장 리처드 브랜슨, 바디샵 창업자 고(故) 아니타 로딕, 스타워즈의 감독 조지 루카스 등 천문학적인 부를 성취한 사람들에겐 6가지 공통점이 있다” 영국 일간 더 타임스는 13일 베스트셀러 작가 폴 맥케나가 세계적인 기업가들을 인터뷰한 끝에 발견했다는 `부(富)의 6단계 원칙’을 소개했다. 이 여섯 단계의 원칙은 기업경영에서의 성공뿐 아니라 모든 분야의 성공전략으로 사용될 수 있다는 것이 맥케나의 주장이다.
일단 성공을 향한 첫번째 원칙은 `열정이 있는 분야에서 일을 시작하라’는 것. 성공을 위해선 수많은 시간을 투자해 일을 해야 하기 때문에 이왕이면 좋아하는 분야를 선택하는 것이 유리하다는 것이다. 물론 열정은 반드시 좋아하는 분야와 일치하는 것은 아니다. 바디샵의 경우 기존 화장품업계에 맞서 안전하고 환경친화적인 대안을 제시하겠다는 아니타 로딕의 신념이 세계적인 성공으로 연결된 케이스다.
두번째 원칙은 `자신이 선택한 분야에서 새로운 가치를 창출할 방법을 강구하라’는 것. 선택한 분야에서 성공하기 위해선 분석 작업이 필수적이란 설명이다. 맥케나는 `이 분야에서 성공한 사업가는 누굴까’, `그 사람은 왜 성공했을까’, `그 사람이 다른 경쟁자보다 나은 점은 무얼까’, `이 분야에서 시도되지 않은 것이 있을까’ `소비자가 원하는 것이 무얼까’ 등의 순서로 자신의 분야를 분석해보라고 조언했다.
세번째 원칙은 `행동에 들어가기 전 머릿속에서 경영의 세세한 부분까지 구상하라’다. 세계적으로 성공한 기업가 중엔 무턱대고 뛰어드는 식의 행동을 벌인 사람은 없었다는 것. 리조트계의 황제 솔 커즈너의 경우 한 지역에 호텔을 건설하기 전 머릿속에서 호텔의 외관뿐 아니라 건물 표면의 질감과 주변환경의 변화까지 그려본 뒤 사업을 시작했다는 설명이다.
`정확한 평가 후 위험을 감수하라’는 게 네번째 원칙이다. 성공을 위해선 위험을 기꺼이 감수하는 것이 기업가의 태도인데 정확한 계산이 선행돼야 한다는 것이다. 영화 스타워즈를 감독한 뒤 상표권을 통해 천문학적인 돈을 벌어들인 조지 루카스가 대표적인 예다. 루카스는 스타워즈 개봉 전 영화 흥행이 실패하더라도 소수의 열혈팬들을 대상으로 각종 상품을 판매할 경우 충분한 이득을 얻을 수 있을 것이라고 판단했다는 설명이다.
`행동은 빠르게’가 다섯번째 원칙이다. 성공한 기업가들은 대부분 구상이 끝난 뒤 24시간 내에 행동에 뛰어드는 것으로 알려졌다. 맥케나는 “교육 수준이나 자본의 수준에 상관없이 빠르게 행동할 수만 있다면 당장 세계적인 기업가들과 같은 급으로 올라설 수 있다”고 지적했다.
성공을 위한 마지막 원칙은 `위기를 예상하고, 실패 속에서 교훈을 얻은 뒤 계속 전진하라’는 것. 낙관주의자가 될 필요는 없지만, 위기가 올 때마다 좌절하는 식으로는 성공을 할 수 없다는 것이다. 사업에 위기가 발생하는 것은 당연한 것인 만큼 위기를 창조적 문제해결 기술을 익힐 기회로 간주하되, 만약 문제를 해결하지 못하더라도 좌절하지 말고 새로운 사업을 벌이라는 조언이다.
OpenGL Shader – 19
GLSL 예제 – Flatten Shader(납작 쉐이더? =_=;)
원문 : http://www.lighthouse3d.com/opengl/glsl/index.php?flatten
쉐이더 프로그래밍은 3차원 장면에 새로운 효과를 넣는데 매우 유용하다. 이 작은 예는 버텍스가 기묘한 방법으로 가공되는 것을 보여준다.
먼저 3D 모델을 납작하게 렌더링시키기 위해, 모델뷰 변환을 적용하기 전에 z 좌표의 값을 0으로 설정한다. 아래의 버텍스 쉐이더가 이 연산을 수행한다.
void main(void)
{
vec4 v = vec4(gl_Vertex);
v.z = 0.0;
gl_Position = gl_ModelViewProjectionMatrix * v;
}위의 코드를 보면, 먼저 지역변수(v)에 gl_Vertex를 복사하고 있다. gl_Vertex는 GLSL에서 제공하는 Attribute 변수이며, 버텍스 쉐이더가 수행되는 동안에는 읽기전용으로 사용할 수 있는 변수이다. 읽기전용이기 때문에 지역변수에 복사하여 값을 변환시킨것이다.
프레그먼트 쉐이더는 단지 색상만을 지정하므로, 이전 섹션(Hello World 예제)에서 제공한 코드와 동일하다.
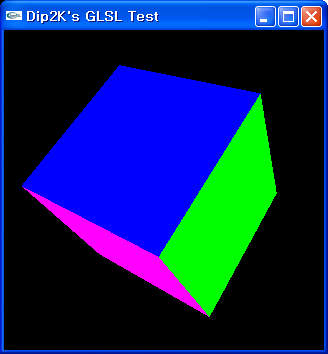
이 쉐이더는 각 버텍스의 z 좌표를 0으로 지정한다. 주전자 3D 모델에 적용을 해보면, 아래의 그림처럼 납작해진 것으로 표현된다.
 됐다. 이제 여기서 좀 응용을 해보자. 버텍스의 z값을 sin함수와 sin함수의 변수는 버텍스의 x좌표로 해면 주전자 모델이 너울거리는 것처럼 표시된다.
됐다. 이제 여기서 좀 응용을 해보자. 버텍스의 z값을 sin함수와 sin함수의 변수는 버텍스의 x좌표로 해면 주전자 모델이 너울거리는 것처럼 표시된다.
void main(void)
{
vec4 v = vec4(gl_Vertex);
v.z = sin(5.0 * v.x) * 0.25;
gl_Position = gl_ModelViewProjectionMatrix * v;
} 이제 이 간단한 예제에 마지막으로 버텍스 에니메이션 효과를 적용해보자. 이 효과를 위해서, 시간을 추적하거나 프레임 카운터를 위한 변수가 필요하다. A vertex shader can’t keep track of values between vertices, let alone between frames. 그래서 OpenGL 어플리케이션에 변수를 하나 정의하고, 이 변수를 Uniform 변수로 쉐이더에 넘겨야 한다. OpenGL 어플리케이션에 “time”이라는 이름의 변수가 있는데, 이변수는 프레임을 카운터하고, 같은 이름의 Uniform 변수가 쉐이더 안에 있다.
이제 이 간단한 예제에 마지막으로 버텍스 에니메이션 효과를 적용해보자. 이 효과를 위해서, 시간을 추적하거나 프레임 카운터를 위한 변수가 필요하다. A vertex shader can’t keep track of values between vertices, let alone between frames. 그래서 OpenGL 어플리케이션에 변수를 하나 정의하고, 이 변수를 Uniform 변수로 쉐이더에 넘겨야 한다. OpenGL 어플리케이션에 “time”이라는 이름의 변수가 있는데, 이변수는 프레임을 카운터하고, 같은 이름의 Uniform 변수가 쉐이더 안에 있다.
버텍스 쉐이더에 대한 코드는 다음과 같다.
uniform float time;
void main(void)
{
vec4 v = vec4(gl_Vertex);
v.z = sin(5.0*v.x + time*0.01)*0.25;
gl_Position = gl_ModelViewProjectionMatrix * v;
}Uniform 변수를 설명한 섹션에서 언급했듯, OpenGL 어플리케이션에서는 다음 두단계가 필요하다.
- setup : Uniform 변수의 위치를 얻는다.
- render : Uniform 변수를 갱신한다.
setup 부분은 다음 코드와 같다.
loc = glGetUniformLocationARB(p, "time");위의 코드에서 인자 p는 쉐이더 프로그램의 헨들이고, time은 버텍스 쉐이더에서 정의한 Uniform 변수의 이름이다. loc 변수는 GLint 형이며 render 함수에서 접근할 수 있는 위치에 정의되어야 한다.
render 함수는 아래와 같다.
void renderScene(void)
{
glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT);
glLoadIdentity();
gluLootAt(0, 0, 5, 0, 0, 0, 0, 1, 0);
glUniform1fARB(loc, time);
glutSolidTeaport(1);
time += 0.1;
glutSwapBuffers();
}time 변수는 초기화부분에서 임의값으로 초기화되었을 것이고 매 프레임마다 증가된다.
여기까지의 예제 코드에 대한 전체 코드는 아래를 통해 다운로드 받길 바란다.
OpenGL Shader – 18
GLSL 예제 : Color Shader
원문 : http://www.lighthouse3d.com/opengl/glsl/index.php?color
GLSL은 OpenGL 상태의 일부분에 접근할 수 있다. 이 섹션에서는 glColor를 사용하는 OpenGL 어플리케이션의 색상에 어떻게 접근하는지를 살펴보겠다.
GLSL은 현재의 색상에 대한 Attribute 변수를 가지고 있다. 또한 버텍스 쉐이더로부터 프레그먼트 쉐이더로 전달되는 색상을 얻기 위한 Varying 변수를 가지고 있다.
attribute vec4 gl_Color;
varying vec4 gl_FrontColor; // 버텍스 쉐이더에서 쓰기 가능
varying vec4 gl_BackColor; // 버텍스 쉐이더에서 쓰기 가능
varying vec4 gl_Color; // 프레그먼트 쉐이더에서 읽기 가능아이디어는 다음과 같다.
- OpenGL 어플리케이션은 glColor 함수를 사용해서 색상값을 보낸다.
- 버텍스 쉐이더는 gl_Color Attribute 변수로 색상값을 받는다.
- 버텍스 쉐이더는 앞면과 뒷면의 색상을 계산하고, gl_FrontColor과 gl_BackColor에 저장한다.
- 프레그먼트 쉐이더는 gl_Color Varying 변수로 보간된 색상을 받는데, 이 색상은 현재의 프리미티브의 방향에 따라 다르다. 예를들어 보간은 gl_FrontColor나 gl_BackColor 값을 사용해서 보간된다.
- 프레그먼트 쉐이더는 gl_Color 값에 기반해서 gl_FragColor를 설정한다.
varying 변수는 버텍스 쉐이더와 프레그먼트 쉐이더 모두에서 같은 이름으로 선언되어져야한다. 여기서의 파악해야할 주요 내용은, 버텍스 쉐이더안에는 2개의 변수가 있는데, 바로 gl_FrontColor와 gl_BackColor이며, 현재의 프리미티브의 면의 방향에 따라 gl_Color의 값이 자동으로 산출되어 진다는 것이다. 여기서 gl_Color Attribute 변수와 gl_Color Varying 변수 사이에는 어떤 충돌도 없다는 점인데, gl_Color Attribute 변수는 버텍스 쉐이더에서만 볼 수 있고 gl_Color Varying 변수는 프레그먼트 쉐이더에서 볼 수 있기 때문이다.
설명은 충분이 했고, 버텍스 쉐이더에 대한 코드를 살펴보자. 여기서 앞면의 색이 계산되어졌다.
void main()
{
gl_FrontColor = gl_Color;
gl_Position = ftransform();
}위의 코드를 들여다보면, gl_Color는 Attribute 변수로써 OpenGL 어플리케이션의 glColor를 통해 값이 지정된다. 이렇게 지정된 색상값을 gl_FrontColor Varying 변수에 입력되어 프레그먼트 쉐이더로 넘겨진다.
프레그먼트 쉐이더를 살펴보자. 버텍스 쉐이더처럼 매우 간단하다.
void main()
{
gl_FragColor = gl_Color;
}간단이 설명해보면, 먼저 버텍스 쉐이더로부터 받은 색상(gl_Color Varying 변수)을 실제 프리미티브의 색상으로 지정하기 위해 gl_FragColor에 지정하고 있다.
위의 실제 예제 코드는 아래를 통해 다운로드 받기 바란다.

실행 결과는 다음과 같다.
PSP-2005 지름
오늘 여자친구님과 데이트가 있어, 잠시 시간도 때울겸해서 몇일전부터 사기로 마음먹은 신형 PSP-2005를 사기 위해 여자친구님이 근무하는 양재역에서 가까운 국제전자상가에 들렸다. 9층에 오르니 온통 게임관련 매장인데, 자리란 자리는 모두 앉어서 끼리끼리 게임에 열중하는 모습이 눈에 띠었다. 인터넷상에서는 품절된 상태인지라 구입이 불가능하여, 매장에서 혹시 매장에서는 구입할지 모른다는 기대반 포기반였는데, 몇군데 매장에 물건이 있었다. 내가 구입한 것의 색상은 피아노-블랙인데, 손때 기름이 장난아니게 뭍는다. 완전… 아모케이스(?)가 다음주에나 나온다니, 그때 구입할때까지 기스않나게 잘써야겠다. 요놈은 좀 쓰다가 팔아야하는 관계로 조심해서 써야지.. 중고로 게임타이틀도 하나 사왔는데, 건담베틀로얄이다. 무식하게 재미없더만… 내 상상력을 불어 넣으니 조금씩 재미있어진다. 닌텐도 DS를 사지 않은게 좀 후회가 되긴하지만…. 이왕 샀으니 재밌게 가지고 놀아야겠다. 공부는 언제할래? -_-;; 아래는 내가 산 PSP-2005의 스틸샷 몇장..



 역시 … 좀 깨끗이 닦고 찍을걸 그랬나…. =_=;
역시 … 좀 깨끗이 닦고 찍을걸 그랬나…. =_=;