
[C] 파일을 포함하는 디렉토리 삭제
하위 디렉토리나 하위 파일을 포함하는 디렉토리를 삭제하는 함수입니다.
int DeleteAllFiles(LPCWSTR szDir, int recur)
{
HANDLE hSrch;
WIN32_FIND_DATA wfd;
int res = 1;
TCHAR DelPath[MAX_PATH];
TCHAR FullPath[MAX_PATH];
TCHAR TempPath[MAX_PATH];
lstrcpy(DelPath, szDir);
lstrcpy(TempPath, szDir);
if (lstrcmp(DelPath + lstrlen(DelPath) - 4, _T("\\*.*")) != 0) {
lstrcat(DelPath, _T("\\*.*"));
}
hSrch = FindFirstFile(DelPath, &wfd);
if (hSrch == INVALID_HANDLE_VALUE) {
if (recur > 0) RemoveDirectory(TempPath);
return -1;
}
while(res) {
wsprintf(FullPath, _T("%s\\%s"), TempPath, wfd.cFileName);
if (wfd.dwFileAttributes & FILE_ATTRIBUTE_READONLY) {
SetFileAttributes(FullPath, FILE_ATTRIBUTE_NORMAL);
}
if (wfd.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY) {
if (lstrcmp(wfd.cFileName, _T("."))
&& lstrcmp(wfd.cFileName, _T(".."))) {
recur++;
DeleteAllFiles(FullPath, recur);
recur--;
}
} else {
DeleteFile(FullPath);
}
res = FindNextFile(hSrch, &wfd);
}
FindClose(hSrch);
if (recur > 0) RemoveDirectory(TempPath);
return 0;
}
성공하면 0을 반환하고 그렇지 않다면 -1을 반환. 인자인 recur이 1이면 szDir로 지정된 디렉토리 자체도 삭제하고 0이라면 szDir로 지정된 디렉토리 자체는 삭제하지 않습니다. 참고로 이 함수는 제가 만드거 아니고 인터넷에서 찾은 것인데 출처를 몰라 =_=; 여튼, 좋은 함수 제공해 주셔서 감사합니다 !
보호된 글: [GIS] 모바일 GIS 엔진, BlackPoint-Xr에서 라벨 효과
[GIS] FingerEyes-Xr for Flex의 편집 기능을 위한 API 설명
FingerEyes-Xr for Flex에서 DBMS에 저장되어 있는 공간 데이터를 마우스를 이용해 사용자가 편집하는 기능을 구현하기 위한 API를 설명하는 문서입니다. DBMS에 저장되어 있는 공간 데이터의 정점을 편집할 수 있도록, 기존 정점을 이동하거나 삭제하고 새로운 정점을 추가하는 기능과 새로운 공간 도형을 생성하고 기존 도형을 삭제하는 기능을 구현하는 튜토리얼 형태의 문서입니다. 또한 편집 이력에 대한 Undo와 Redo에 대한 기능도 설명합니다.
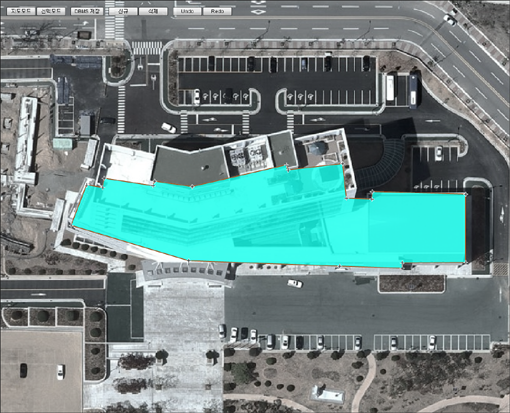
위의 그림은 편집 기능에 대한 API 설명 문서 내용 전반에서 언급하고 있는 예제 화면입니다. 편집 기능에 대한 API 문서는 아래 URL을 통해 다운로드 받을 수 있습니다.

FingerEyes-Xr for Flex에서 편집이 가능한 공간 데이터는 Oracle, MSSQL Server, PostgreSQL와 같은 DBMS에 저장하여 처리될 수 있습니다.
[GIS] FingerEyes-Xr for Flex, ShapeMapLayer의 filterFunction 기능
수치지도 데이터를 처리하는 레이어인 XrShapeMapLayer는 filterFunction이라는 콜백함수 기능을 제공합니다. 이 기능은 공간 서버로부터 공간 데이터를 가져오고 화면에 표시하기 전에 가져온 공간 데이터에 대한 선처리(Preprocessing)을 수행하는 용도로 사용됩니다. 아래의 코드는 XrShapeMapLayer에 filterFunction 콜백함수를 지정하는 코드입니다.
var layer:XrShapeMapLayer = null;
layer = map.layers.getLayer("LAYER_NAME") as XrShapeMapLayer;
layer.filterFunction = filterFunction;
여기서 filterFunction은 다음과 같은 인자를 갖습니다. FingerEyes-Xr 버전 2.2를 기준으로 다릅니다.
ㅡ FingerEyes-Xr version 2.2 이상
// FingerEyes-Xr version 2.2 이상
private function filterFunction(fid:uint,
shpLyr:XrShapeMapLayer, index:uint, cntRows:uint):void
{
// ...
}
ㅡ FingerEyes-Xr version 2.2 미만
// FingerEyes-Xr version 2.2 미만
private function filterFunction(fid:uint,
shpSet:XrShapeSet, attSet:XrAttributeSet):void
{
// ...
}
이 기능은 다양한 용도로 사용될 수 있습니다. 예를 들자면 어떤 기준에 부합되지 않으면 공간 데이터를 화면에 그리기 전에 공간 데이터를 제거함으로써 화면에 표시하지 않는 경우입니다.
ㅡ FingerEyes-Xr version 2.2 이상
// FingerEyes-Xr version 2.2 이상
private function filterFunction(fid:uint,
shpLyr:XrShapeMapLayer, index:uint, cntRows:uint):void
{
var shpSet = shpLyr.shapeSet;
var attSet = shpLyr.attributeSet;
var attr:XrAttribute = attSet.rows[fid];
var bBeDelete:Boolean = true;
var from:int, to:int, value:int;
value = attr.getValueAsInt(13);
from = this.nsDeathFrom.value;
to = this.nsDeathTo.value;
if(value >= from && value <= to) bBeDelete = false;
f(bBeDelete) {
shpSet.removeRow(fid);
attSet.removeRow(fid);
}
}
ㅡ FingerEyes-Xr version 2.2 미만
// FingerEyes-Xr version 2.2 미만
private function filterFunction(fid:uint,
shpSet:XrShapeSet, attSet:XrAttributeSet):void
{
var attr:XrAttribute = attSet.rows[fid];
var bBeDelete:Boolean = true;
var from:int, to:int, value:int;
value = attr.getValueAsInt(13);
from = this.nsDeathFrom.value;
to = this.nsDeathTo.value;
if(value >= from && value <= to) bBeDelete = false;
f(bBeDelete) {
shpSet.removeRow(fid);
attSet.removeRow(fid);
}
}
위의 코드는 공간 데이터에 대한 13번째 속성값이 정해진 범위값에 들어가지 않을 경우 그리기 전에 제거함으로써 화면에 표시하지 않도록 하는 코드예입니다.