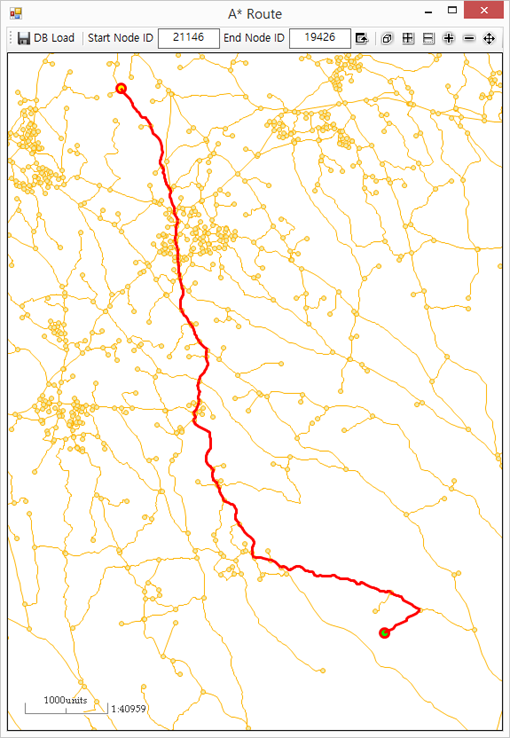
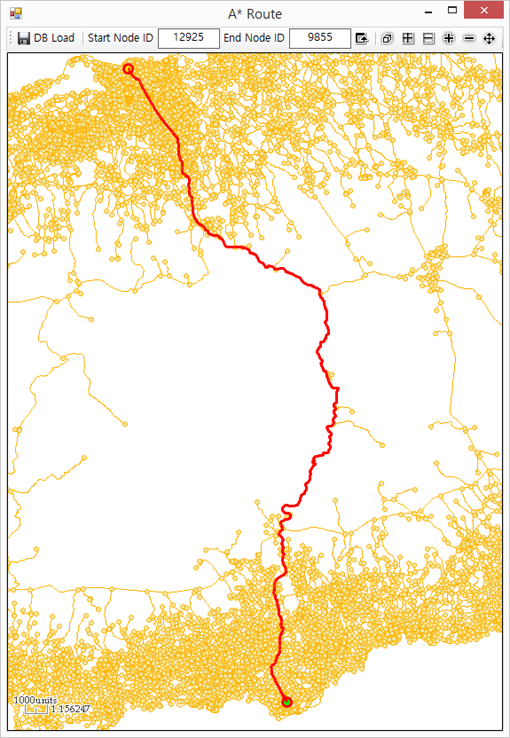
안드로이드 기반의 모바일 GIS 엔진인 BlackPoint-Xr을 이용해 개발한 “지반재해 현장관리 시스템 v2016”을 간단히 소개해 봅니다.
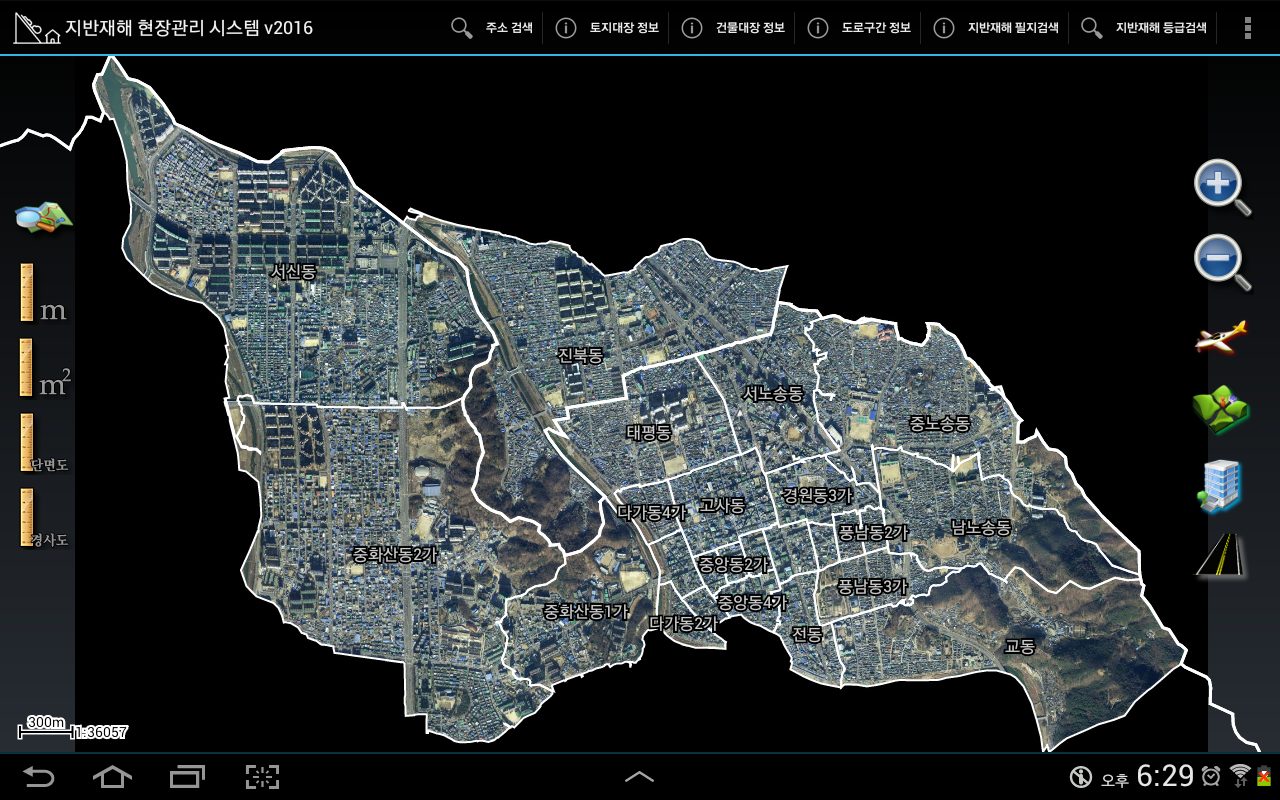
맵(Map)하면 항공영상과 수치지도의 표시에서 시작합니다. 해당 필지를 선택하면 아래처럼 선택된 필지에 대한 지반재해 정보가 표시됩니다.
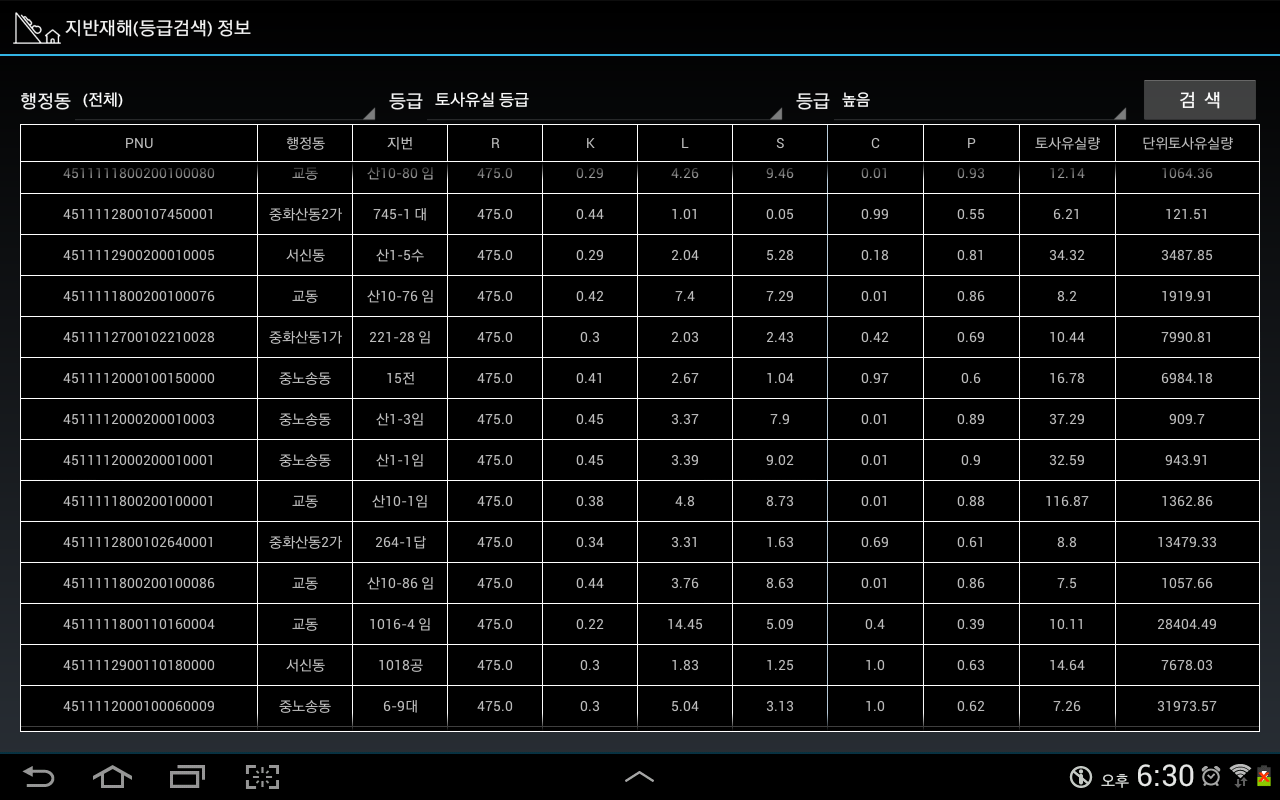
그리고 지반재해에 대한 등급을 속성에 대해 검색할 수 있는 아래의 같은 UI를 제공해서 검색하고자 하는 정보를 효과적으로 검색할 수 있도록 하였습니다.
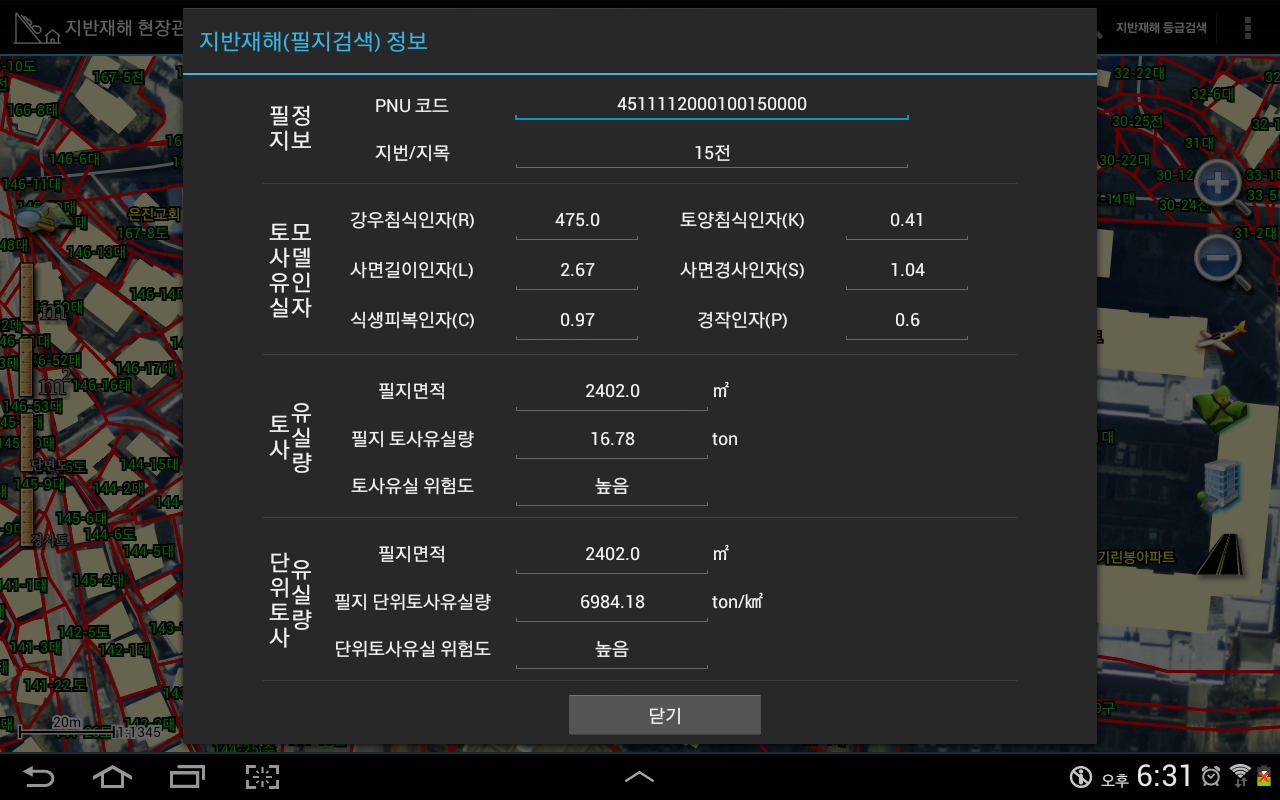
토사유실량의 산정은 USLE를 통해 계산할 수 있습니다. USLE는 Universal Soil Loss Equation의 앞자를 따온 것으로 이름에서도 알 수 있듯이 토양 유실(Soil Loss)에 대해 가장 많이 사용되는 식입니다. USLE는 아래와 같습니다.
![]()
위의 식에서 R, K, LS, C, P 인자가 보이는데요. 각 인자는 아래와 같습니다.
- R – 강우침식인자로써, 일반적으로 연간등강우침식도를 통해 얻을 수 있습니다.
- K – 토양침식인자로써, 1:25000의 정밀토양도를 통해 얻을 수 있습니다.
- LS – 경사도 및 경사장인자로써 1:5000 등고선 수치지도를 통해 얻을 수 있습니다.
- C – 식생피복인자로써 토지피복도를 통해 얻을 수 있습니다.
- P – 경작인자로써 토지이용현황도를 통해 얻을 수 있습니다.
유사유출량의 단위는 톤(Ton)이며, 위의 식을 통해 알 수 있듯이 토사유출은 강우와 토양침식, 지형의 경사도, 지형위에서 자라고 있는 식생 및 경작이 주로 영향을 미친다는 것을 알 수 있습니다.
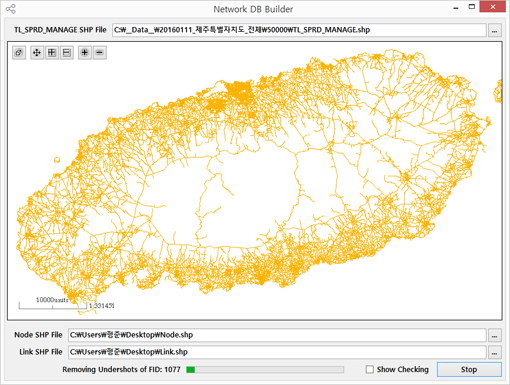
끝으로 아래의 그림은 이 시스템에서 사용한 공간 데이터가 모바일 환경에서 사용되기 위한 변환에 대해 설명을 하고 있습니다.