이 글의 원문은 https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_objdetect/py_face_detection/py_face_detection.html 입니다.
Haar 특징기반 다단계 분류자(Feature-based Cascade Classifiers)를 이용한 물체 검출은 Paul Viola와 Michael Jones이 2001년에 발표한 논문, “Rapid Object Detection using a Boosted Cascade of Simple Features”에서 제안된 효과적인 물체 검출 방법입니다. 이는 검출할 대상이 되는 물체가 있는 이미지와 없는 이미지(각각을 Positive Image와 Negative Image라고 함)을 최대한 많이 활용해서 다단계 함수를 훈련시키는 기계학습 방식입니다.
이 글에서는 검출할 대상을 얼굴로 시험해 봅니다. 처음에, 이 알고리즘은 분류자(Classifier)를 훈련시키기 위해 매우 많은 훈련용 이미지가 필요합니다. 이 이미지는 앞서 언급한 Positive와 Negative 이미지입니다. 다음 단계는 특징들(Features)를 추출해야 합니다. 이를 위해, 아래 그림에서의 Haar 특징이 사용됩니다. 이는 마치 컨볼루션 커널(Convolutional Kernel)과 같습니다. 각 특징은 하얀색 사각형에서의 픽셀값의 합을 검정색 사각형 영역의 픽셀값의 합에서 뺀 값입니다.
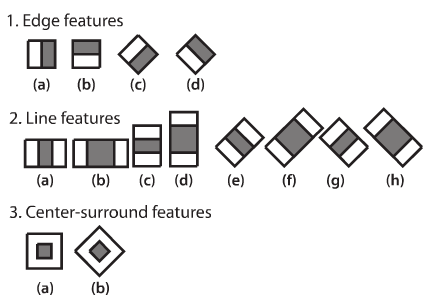
많은 특징을 계산하기 위해 이미지에 적용할 각 커널에 대한 모든 가능한 크기와 위치를 고려해야 합니다. 얼마나 많은 계산이 필요할까요? 24×24 크기의 이미지만 해도 160000개 이상의 특징 결과값이 존재합니다. 각 특징을 계산하기 위해서, 하얀색 영역과 검정색 영역의 픽셀의 합을 얻어야 합니다. 이를 위해, 논문에서는 인테그랄(Integral) 이미지를 언급합니다. 이 이미지는 픽셀의 합의 계산을 단순화 시켜 줍니다. 이는 알고리즘 속도를 매우 빠르게 개선시켜 줍니다.
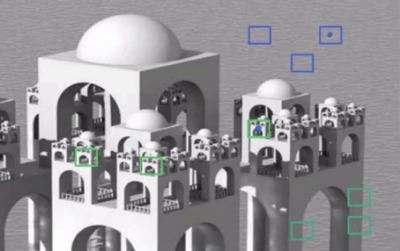
그러나 이렇게 계산된 모든 특징들 중 대부분이 적합하지 않습니다. 예를들어, 아래의 이미지를 봅시다. 첫번째 선택된 특징은 눈 영역이 코나 뺨 영역보다 자주 어둡다라는 점에 주목합니다. 두번째 선택된 특징은 눈이 미간보다 어둡다는 것에 주목합니다. 그러나 뺨이나 다른 곳에 적용된 동일한 이미지는 부적절합니다. 그래서 160000개 이상의 특징 중 최고의 특징을 어떻게 선택해야 할 것인가가 문제입니다. 이 문제를 Adaboost가 해결해 냈습니다.

이를 위해서, 모든 훈련 이미지들에 대해 각각의 모든 특징을 적용합니다. 각 특징에 대해, 이미지 상에 얼굴이 있는지 없는지(즉 positive 또는 negative 인지)를 분류될 최고의 임계값을 찾습니다. 그러나 명백하게, 여기에는 오류와 잘못된 분류가 존재합니다. 최소한의 에러율로 특징을 선택하는데, 이는 얼굴 이미지인지, 얼굴이 아닌 이미지인지를 아주 잘 분류한다는 것을 의미합니다. (이런 처리는 말처럼 간단하지 않습니다. 각 이미지는 시작부터 동일한 가중치가 주어집니다. 각각의 분류 후에, 잘못 분류된 이미지의 가중치는 증가합니다. 그러면 다시 같은 절차가 수행됩니다. 새로운 에러율이 얻어지거나 원하는 개수의 특징점이 발견됩니다.)
최종 분류자는 이러한 약한 분류자 들의 가중치 합입니다. 약하다고 하는 이유는 분류자 하나만으로 이미지를 분류하지 못하고 분류자들이 모여야만 제대로 이미지를 분류할 수 있기 때문입니다. 논문에서는 200개의 특징만으로도 90%의 정확도를 제공한다고 합니다. 최종적으로 약 6000개의 특징점이 도출됩니다. (160000개 이상의 특징점이 6000개의 특징점으로 줄었다는 것은 엄청난 이득입니다.)
이제 이미지를 취합니다. 각 24×24 크기의 윈도우를 잡습니다. 6000개의 특징을 이미지에 적용합니다. 얼굴이 있는지 없는지 검사합니다. 그런데, 이 방식은 시간 소모도 많고 비효율적입니다. 논문의 저자는 이를 위해 좋은 해결책을 제시합니다.
이미지에서, 이미지 영역의 대부분은 얼굴이 아닌 영역입니다. 이 생각은 윈도우가 얼굴 영역이 아닌지를 검사하는 간단한 방법이 됩니다. 만약 얼굴 영역이 아니라면, 이를 단번에 버립니다. 다시 수행하지 않습니다. 대신 얼굴이 있는 곳의 영역에 초점을 맞춥니다.
이를 위해 논문의 저자들은 다단계 분류자(Cascade of Classifiers)의 개념을 소개합니다. 윈도우에 대한 6000개의 모든 특징을 적용하는 대신, 분류자의 다른 단계로 특징을 묶고 하나씩 하나씩 적용하는 것입니다. (보통 처음 몇몇 단계는 매우 적은 수의 특징을 갖습니다.) 만약 윈도우가 첫번째 단계에서 실패하면 버립니다. 나머지 특징들은 더 이상 고려하지 않습니다. 만약 통과되면 특징의 두번째 단계를 정용하고 이를 계속 반복합니다. 모든 단계를 통과한 윈도우가 얼굴 영역이 됩니다!!
이제 이 Haar Cascades 알고리즘을 구현한 OpenCV의 함수를 이용해 얼굴을 검출해 보는 코드를 살펴 보겠습니다.
OpenCV는 트레이너와 검출자 모드를 제공합니다. 차량이나 비행기와 같은 물체 검출을 위한 자신만의 훈련이 필요하다면 OpneCV를 이용해 훈련시킬 수 있습니다. (참조 : https://docs.opencv.org/2.4/doc/user_guide/ug_traincascade.html)
이 글에서는 검출에 대해서만 설명합니다. OpenCV에서는 이미 얼굴, 눈 등에 대한 미리 훈련된 데이터를 XML 파일 형식으로 제공합니다. 바로 이 XML 분류자 파일을 로드 하는 것이 시작입니다. 그리고 분류할 이미지를 Grayscale로 로드하는 것입니다.
import numpy as np
import cv2
from matplotlib import pyplot as plt
face_cascade = cv2.CascadeClassifier('./data/haar/haarcascade_frontface.xml')
eye_cascade = cv2.CascadeClassifier('./data/haar/haarcascade_eye.xml')
img = cv2.imread('./data/haar/img.jpg')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
다음은 입력 이미지에서 얼굴을 검출하는 것입니다. 만약 얼굴을 발견하면, 발견한 얼굴에 대한 위치를 Rect(x,y,w,h) 형태로 얻을 수 있습니다. 이 위치를 얻었다면, 얼굴에 대한 ROI를 만들고, 이 안에서 눈을 검출합니다. (눈은 얼굴 안에 있으니까요!)
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
for (x,y,w,h) in faces:
cv2.rectangle(img,(x,y),(x+w,y+h),(255,0,0),2)
roi_gray = gray[y:y+h, x:x+w]
roi_color = img[y:y+h, x:x+w]
eyes = eye_cascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.imshow('img',img)
cv2.waitKey(0)
cv2.destroyAllWindows()
실행 결과는 다음과 같습니다.

아이언맨의 얼굴과 캡틴아메리카의 얼굴은 검출되지 못했는데, 이는 훈련 데이터가 정면에서 본 얼굴에 대한 이미지들로 만들어졌기 때문입니다.