이전에 작성한 “PyTorch를 이용한 간단한 머신러닝”이라는 아래의 글에서는 은닉층이 없는 입력과 출력층으로만 구성된 모델을 사용했습니다. 그리고 가중치 및 편향값의 최적화를 위한 방법은 SGD, 즉 확률적 경사하강을 사용했습니다. 정확도는 대략 90%정도 나왔었습니다.
이에 대해 은닉층을 2개 추가하고 매개변수의 최적화를 위한 방식을 SGD가 아닌 Adam을 사용하여 정확도를 향상시켜 보겠습니다. 은닉층이 추가 되었으므로 활성화 함수가 필요한데, 역전파에서 미분값 소실(Vanishing Gradient)이 발생할 가능성이 큰 시그모이드 함수가 아닌 ReLU 함수를 사용합니다. 즉, 모델은 다음과 같습니다.
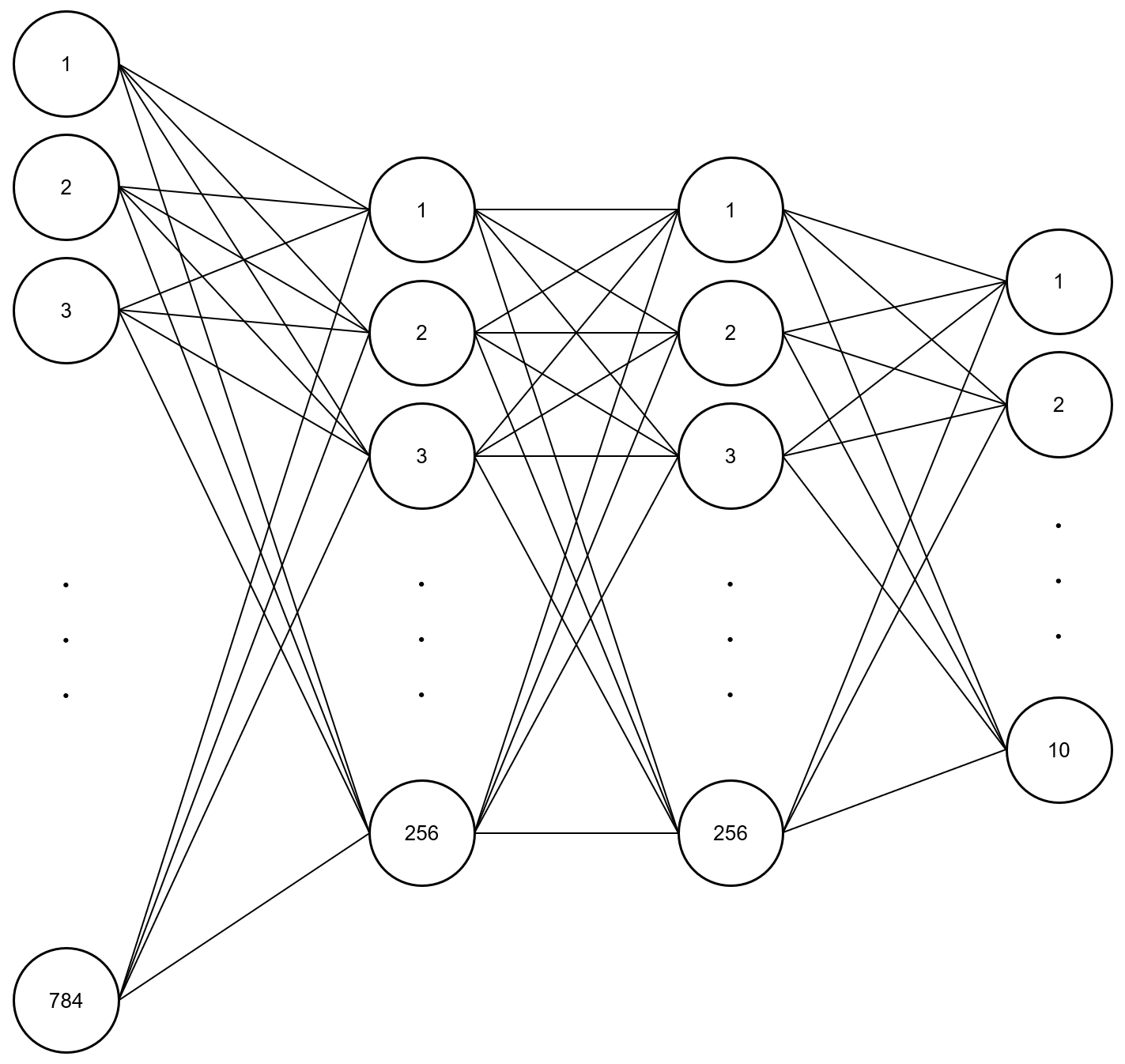
위 모델을 구성하기 위한 PyTorch의 코드는 다음과 같습니다.
linear1 = torch.nn.Linear(784, 256, bias=True).to(device) linear2 = torch.nn.Linear(256, 256, bias=True).to(device) linear3 = torch.nn.Linear(256, 10, bias=True).to(device) relu = torch.nn.ReLU() model = torch.nn.Sequential(linear1, relu, linear2, relu, linear3).to(device)
그리고 매개변수에 대한 최적화 방법을 Adam을 사용하므로 이에 대한 코드는 아래와 같구요. 각 최적화 방식이 어떤식으로 작동하는지 시각적으로 확인할 수 있는 유용한 사이트인 http://www.denizyuret.com/2015/03/alec-radfords-animations-for.html을 참고하시기 바랍니다.
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
기존의 소스코드에서 위의 변경된 부분이 반영된 전체 코드는 아래와 같습니다.
import torch
import torchvision
batch_size = 1000
mnist_train = torchvision.datasets.MNIST(root="MNIST_data/", train=True, transform=torchvision.transforms.ToTensor(), download=True)
mnist_test = torchvision.datasets.MNIST(root="MNIST_data/", train=False, transform=torchvision.transforms.ToTensor(), download=True)
data_loader = torch.utils.data.DataLoader(mnist_train, batch_size=batch_size, shuffle=True, drop_last=True)
device = torch.device("cuda:0")
linear1 = torch.nn.Linear(784, 256, bias=True).to(device)
linear2 = torch.nn.Linear(256, 256, bias=True).to(device)
linear3 = torch.nn.Linear(256, 10, bias=True).to(device)
relu = torch.nn.ReLU()
model = torch.nn.Sequential(linear1, relu, linear2, relu, linear3).to(device)
loss = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
total_batch = len(data_loader)
training_epochs = 15
for epoch in range(training_epochs):
total_cost = 0
for X, Y in data_loader:
X = X.view(-1, 28 * 28).to(device)
Y = Y.to(device)
hypothesis = model(X)
cost = loss(hypothesis, Y)
optimizer.zero_grad()
cost.backward()
optimizer.step()
total_cost += cost
avg_cost = total_cost / total_batch
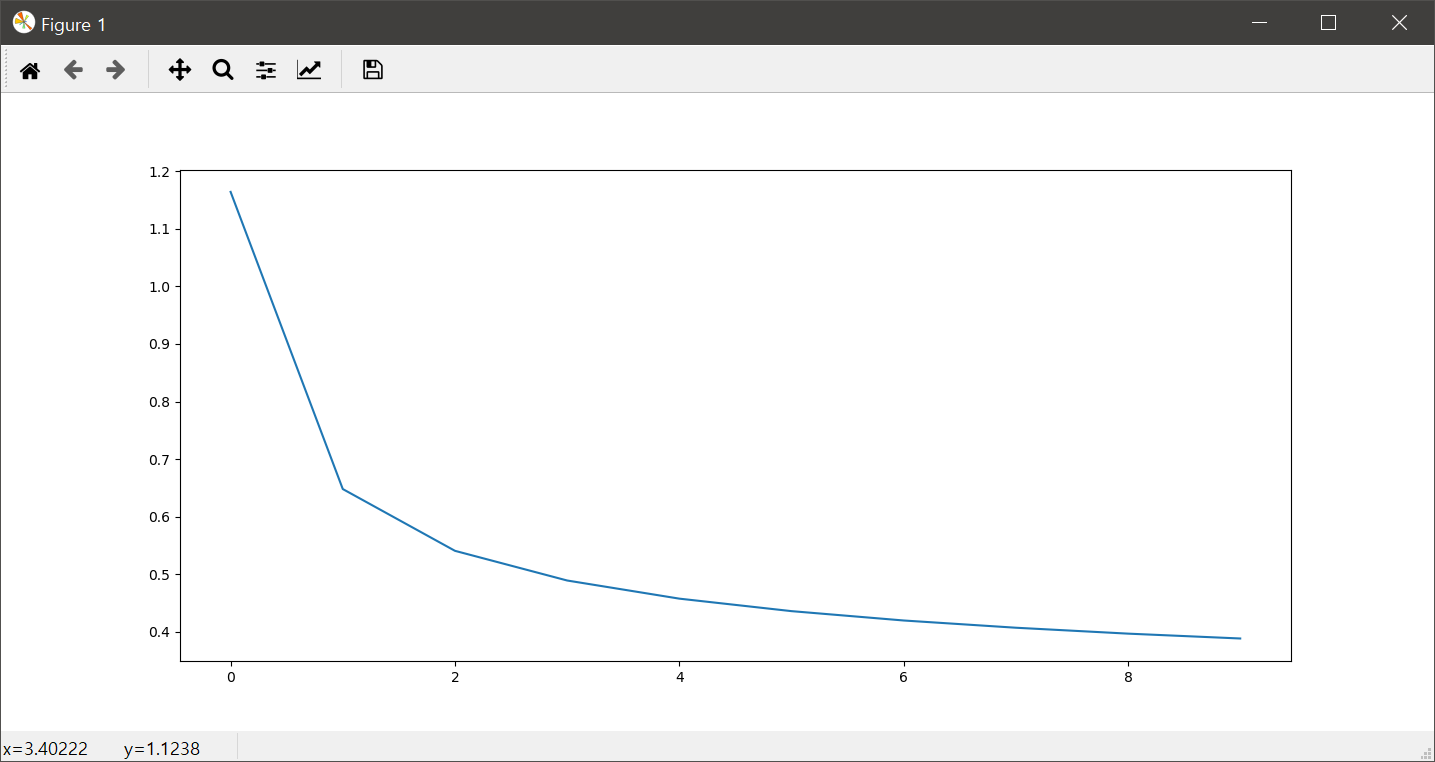
print("Epoch:", "%03d" % (epoch+1), "cost =", "{:.9f}".format(avg_cost))
with torch.no_grad():
X_test = mnist_test.data.view(-1, 28 * 28).float().to(device)
Y_test = mnist_test.targets.to(device)
prediction = model(X_test)
correct_prediction = torch.argmax(prediction, 1) == Y_test
accuracy = correct_prediction.float().mean()
print("Accuracy: ", accuracy.item())
최적화 기법마다 학습률의 값은 다릅니다. 물론 에폭에 대한 반복수도 달라질 수 있습니다. 이러한 모델의 구성과 하이퍼 파라메터인 학습률과 반복 에폭수 등은 AI 전문가가 상황에 따라 결정해야 합니다. 결과적으로 위와 같은 모델의 확장과 최적화 방법의 변경 등을 통한 정확도는 약 97%로 출력되는데, 기존의 90%에서 대폭 향상된 것을 알 수 있습니다.