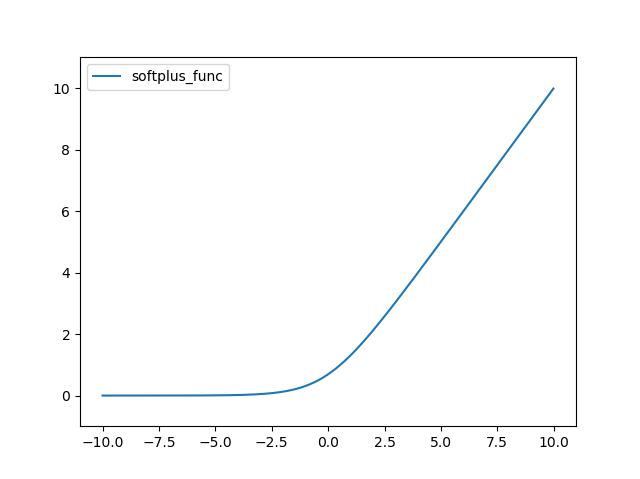
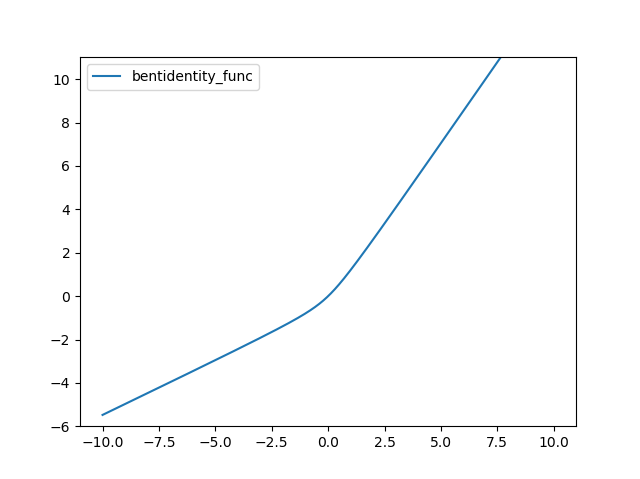
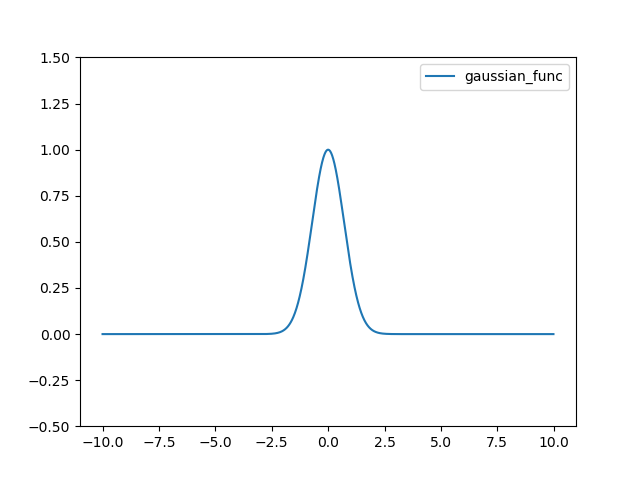
메인 윈도우에서 대화상자를 열고, 대화상자에서 입력한 값을 메인 윈도우에 표시하고하는 경우에 대한 설명입니다. UI 라이브러리는 PyQt5를 사용했습니다. 먼저 메인 모듈에 대한 코드입니다. 참고로 이글은 PyQt5에 대한 최소한의 기초 내용을 파악하고 있는 개발자를 대상으로 합니다.
import sys
from MainWindow import MainWindow
from PyQt5.QtWidgets import *
if __name__ == '__main__':
app = QApplication(sys.argv)
win = MainWindow()
win.show()
sys.exit(app.exec_())
위의 코드에서 메인 윈도우는 MainWindow.py 파일에 정의되어 있으며, 코드는 다음과 같습니다.
import sys
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
from SubWindow import SubWindow
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.setWindowTitle('Main Window')
self.setGeometry(100, 100, 300, 200)
layout = QVBoxLayout()
layout.addStretch(1)
label = QLabel("미지정")
label.setAlignment(Qt.AlignCenter)
font = label.font()
font.setPointSize(30)
label.setFont(font)
self.label = label
btn = QPushButton("값 얻어오기")
btn.clicked.connect(self.onButtonClicked)
layout.addWidget(label)
layout.addWidget(btn)
layout.addStretch(1)
centralWidget = QWidget()
centralWidget.setLayout(layout)
self.setCentralWidget(centralWidget)
def onButtonClicked(self):
win = SubWindow()
r = win.showModal()
if r:
text = win.edit.text()
self.label.setText(text)
def show(self):
super().show()
위의 메인 윈도우는 아래와 같은 UI를 표시합니다.
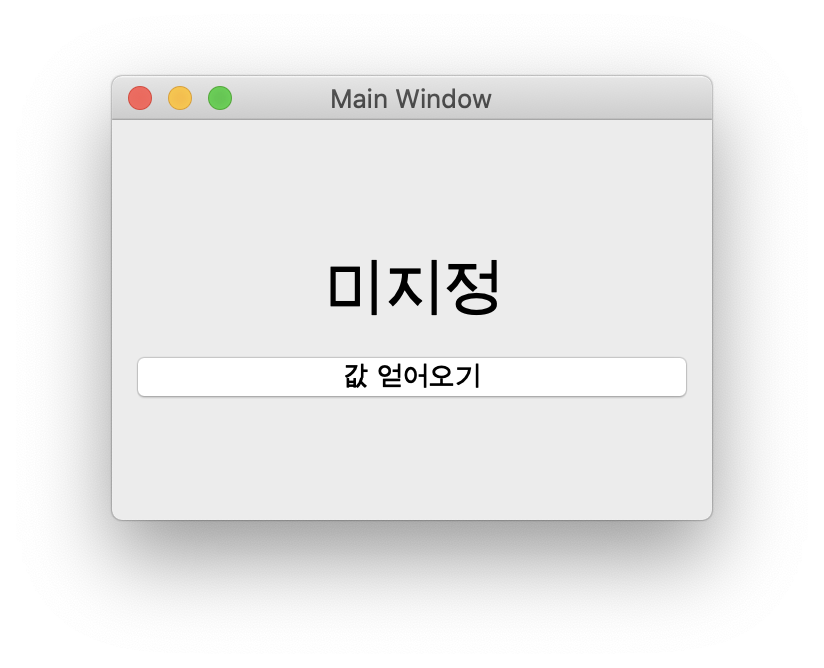
“값 얻어오기” 버튼을 클릭하면 대화창을 표시되며, 표시된 대화창에서 텍스트를 입력하고 대화창의 “확인” 버튼을 클릭하면 대화창에서 입력한 텍스트값을 메인 윈도우의 라벨 위젯에 표시하게 됩니다. 대화창에 대한 코드 파일은 SubWindow.py이며 다음과 같습니다.
import sys
from PyQt5.QtWidgets import *
class SubWindow(QDialog):
def __init__(self):
super().__init__()
self.initUI()
def initUI(self):
self.setWindowTitle('Sub Window')
self.setGeometry(100, 100, 200, 100)
layout = QVBoxLayout()
layout.addStretch(1)
edit = QLineEdit()
font = edit.font()
font.setPointSize(20)
edit.setFont(font)
self.edit = edit
subLayout = QHBoxLayout()
btnOK = QPushButton("확인")
btnOK.clicked.connect(self.onOKButtonClicked)
btnCancel = QPushButton("취소")
btnCancel.clicked.connect(self.onCancelButtonClicked)
layout.addWidget(edit)
subLayout.addWidget(btnOK)
subLayout.addWidget(btnCancel)
layout.addLayout(subLayout)
layout.addStretch(1)
self.setLayout(layout)
def onOKButtonClicked(self):
self.accept()
def onCancelButtonClicked(self):
self.reject()
def showModal(self):
return super().exec_()
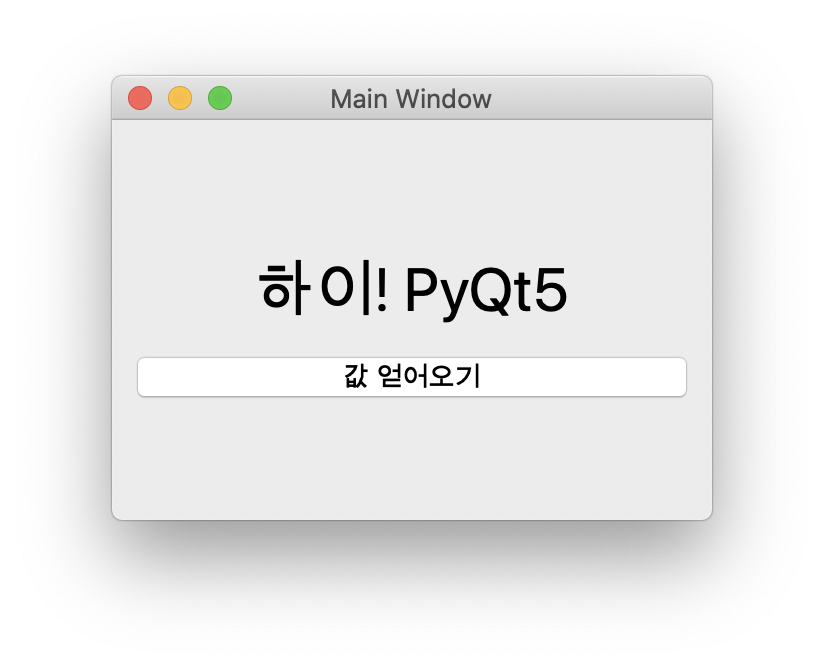
아래는 메인 윈도우에서 위의 코드에 대한 대화창을 표시한 뒤 사용자가 “하이! PyQt5″텍스트를 입력한 화면입니다.
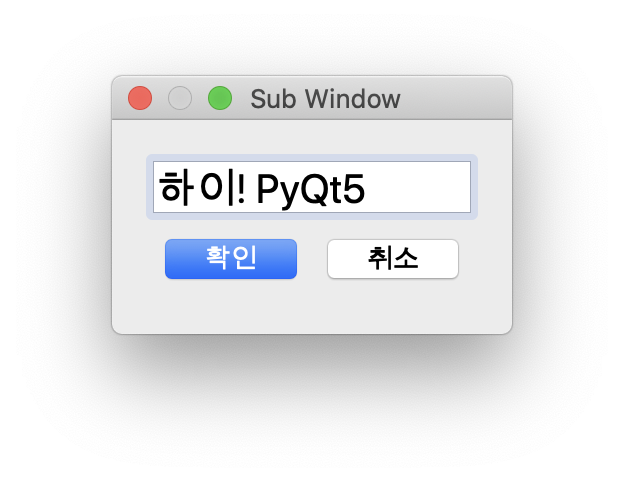
위의 화면에서 닫기 버튼을 클릭하면 창이 닫히고 메인 윈도우에 대화창에서 입력한 텍스트가 표시되는데, 아래와 같습니다.