다익스트라 알고리즘은 시작 노드만을 지정하면, 이 시작 노드에서 다른 모든 노드에 대한 최단 경로들을 분석해 줍니다. 참고로 최단 경로 탐색 알고리즘의 다른 형태로 A*(에이스타) 알고리즘이 있는데요. A* 알고리즘은 시작 노드에서 목적지 노드를 지정해주면 이 2개의 노드 간의 최단 경로 하나만을 분석해 줍니다.
이 글은 다익스트라 알고리즘에 대한 이런 저런 장황한 설명을 배제하고 실제 예를 들어, 그 예에 대한 최단 경로 탐색을 위한 다익스트라 알고리즘에 대해 설명합니다.
먼저 다음과 같은 예를 들어 보겠습니다.
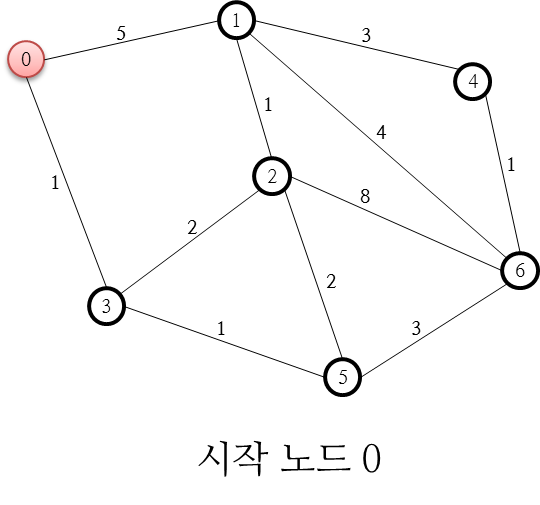
위의 그림을 간단히 설명하면, 0부터 6번까지의 노드(Node)가 존재하고 각 노드를 연결하는 선인 링크(Link)가 있습니다. 각 링크에는 숫자가 표시되어 있는데요. 이 숫자는 해당 링크를 지나갈때에 소요되는 비용(Cost, 경비)로 생각할 수 있습니다. 예를 들어, 2번 노드와 6번 노드 사이에 비용 8인 링크가 있는데요. 이는 2번 노드에서 6번 노드를 지나간다고 할때 8의 비용이 필요하다는 의미입니다. 비용이 적을 수록 상대적으로 더 좋은 경로이겠지요.
이제 위의 예, 즉 0번 노드를 시작점으로 해서 나머지 1, 2, 3, 4, 5, 6 번 노드를 목적지로 하는 최단 경로 6개를 구할 수 있는 방법이 바로 다익스트라 알고리즘입니다.
이상의 문제 해결을 위해 가장 먼저 시작되는 연산은 다음 그림과 같습니다.
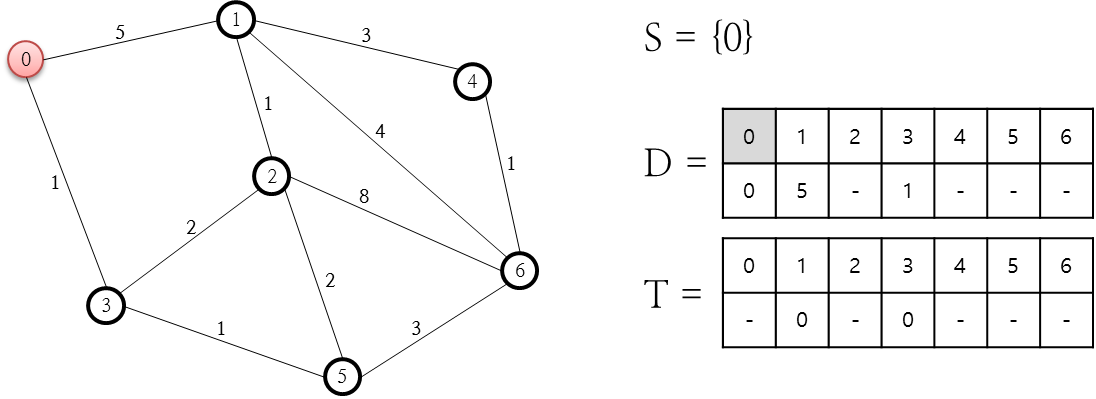
위의 그림에서 S 은 이미 처리가 완결된 노드의 집합인데요. 가장 먼저 시작 노드인 0번을 집어 놓음으로써 0번 노드에 대한 처리를 시작합니다. D 저장소는 0번~6번까지의 노드에 대해, 시작노드로부터 소요되는 비용을 저장하고 있습니다. D 저장소의 상단 행은 노드의 번호이고 하단 행은 시작노드로부터 소요되는 비용입니다. 위 그림에서 D 저장소를 보면 0번 노드는 시작노드이므로 소요되는 비용이 0이고, 0번 노드와 링크로 연결된 1번과 3번 노드는 각각 5와 1의 비용이 소요되는 것으로 기록되어 있습니다. T 저장소는 해당 노드로 가는데 연결된 노드의 번호를 담고 있는데요. T 저장소이 상단 행은 노드의 번호이고 하단 노드는 연결된 노드 번호입니다. 위의 그림을 보면 1번 노드와 3번 노드는 0번 노드와 연결되어 있으므로 0으로 기록되어져 있습니다. 이게 주어진 문제에 대한 다익스트라 알고리즘의 첫번째 처리입니다.
이제 다음 처리에 대한 그림을 살펴 보겠습니다.
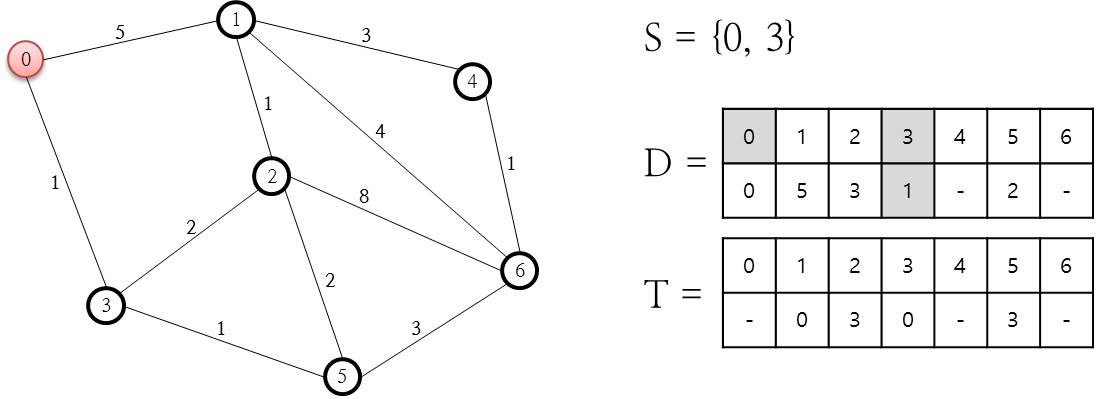
S집합에 3번 노드를 추가했습니다. 이유는 D 저장소에 3번 노드에 대한 비용값이 가장 최소이기 때문입니다. S집합에 3번 노드를 추가함으로써 3번 노드와 링크로 연결된 2번과 5번 노드에 대한 비용값을 계산해 D 저장소에 기록해야 하는데요. 시작 노드인 0번 노드에서 2번 노드까지 가기 위해서 소요되는 비용은 총 3입니다. 이유는 0번-3번-2번 노드로 가야하므로 비용값은 0번-3번 노드로 가는 비용 1과 3번과 2번 노드로 가는 비용 2를 합한 값입니다. 이러한 계산은 D 저장소를 활용하면 쉽게 계산할 수 있는데요. 이미 시작노드에서 각 노드로 가는 비용이 계산되어 있기 때문에 마지막 노드로 가는 비용만을 더해주면 되기 때문입니다. 5번 노드에 대한 비용은 동일한 방식으로 1+1인 2가 됩니다. 그리고 T 저장소도 각 노드에 대해 이전에 연결된 노드값을 기록해 둡니다. T 저장소의 2번과 5번 노드는 3번 노드를 통해 연결되어 있으므로 3을 기록합니다. 다음 처리에 대한 그림을 살펴봅시다.
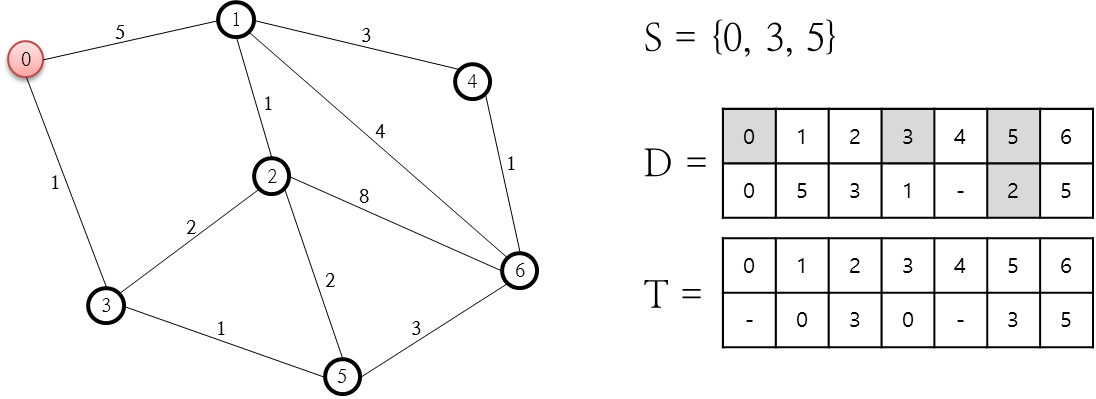
S 집합에 5를 추가했습니다. 이는 이미 처리가 완료된 노드 이외의 노드 중 5번 노드의 비용이 2로 가장 최소이기 때문입니다. 이미 처리가 완료된 노드인지 S 집합에 존재하는지를 보면 알 수 있습니다. 5번 노드에 대해 연결된 노드는 2, 3, 6번 노드인데요. 이미 3번은 처리가 완료되었으므로 2번 노드와 3번 노드에 대해 D 저장소의 값을 갱신해야 합니다. 5번 노드를 거쳐 2번 노드를 갈 경우 소요되는 비용은 2+2로 4입니다. 이 값은 이미 전 단계에서 계산된 비용값(3)보다 크므로 무시합니다. 6번 노드에 대한 비용값은 5번 노드까지 오는데 소요된 비용값(2)와 5번에서 6번 노드로 가는데 추가적으로 필요한 비용 3을 합한 값 5이므로, 이 값을 D 저장소에 기록하고 T 저장소의 6번 노드 값에 5번 노드를 기록합니다. 다음 단계로 넘어 갑니다. 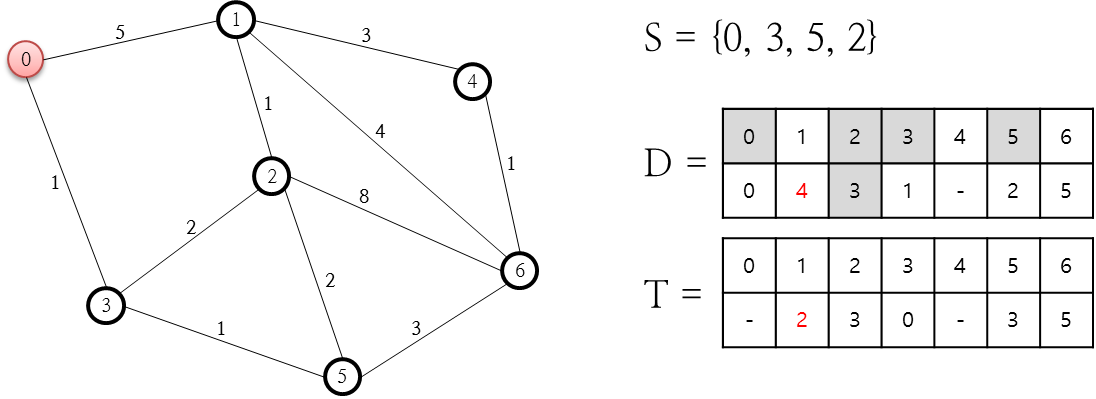
처리가 완결되지 않은 노드 중 비용이 최소인 노드는 2번인데요. 2번 노드와 연결된 노드는 1, 3, 5, 6번 노드입니다. 처리가 완결된 노드를 저장하고 있는 S 집합을 통해 3번 노드와 5번 노드는 더 이상 고려할 필요가 없다는 것을 알 수 있으니, 1, 6번만 고려하면 됩니다. 먼저 1번의 경우 소요되는 비용은 3+1로 4인데요. 이 값은 이전 단계에서 계산된 비용값(5)보다 작으로 D 저장소의 값을 변경 합니다. D 저장소가 변경되면 T 저장소의 값도 2번 노드로 변경합니다. 중요한 부분이므로 위의 그림에서 빨간색으로 표시했습니다. 이제 남은 6번 노드에 대한 비용값을 계산해 보면 3+8로 11인데요. 이 값은 이전 단계에서 계산된 비용인 5보다 크므로 무시합니다. 다음 단계로 진행합니다.
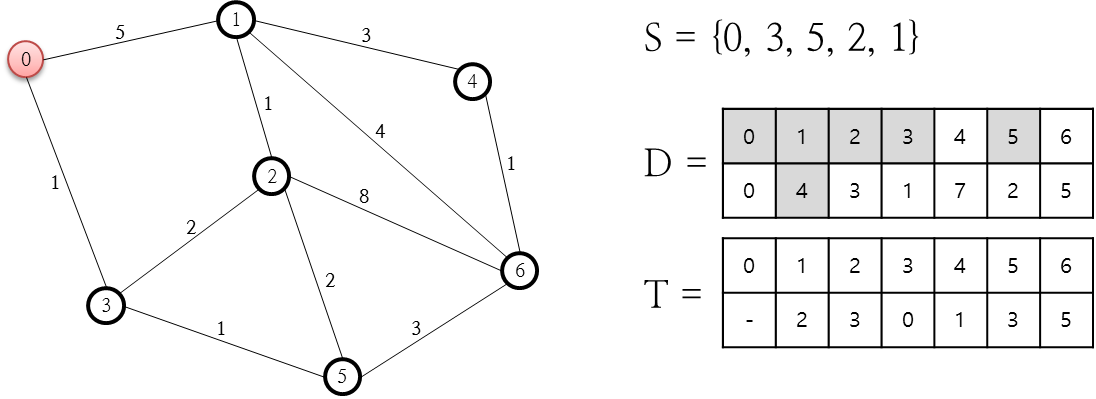
처리가 완료된 노드가 아닌 것 중 1번 노드의 비용이 현재 가장 최소이므로 집합 S에 1번 노드를 추가하고 1번 노드와 연결된 0, 2, 4번 노드 중 완결되지 않은 4번 노드에 대한 비용값을 계산합니다. 4번 노드의 비용값은 4+3으로 7이므로 이 값을 D 저장소에 기록하고 T 저장소에 1번 노드를 기록합니다.
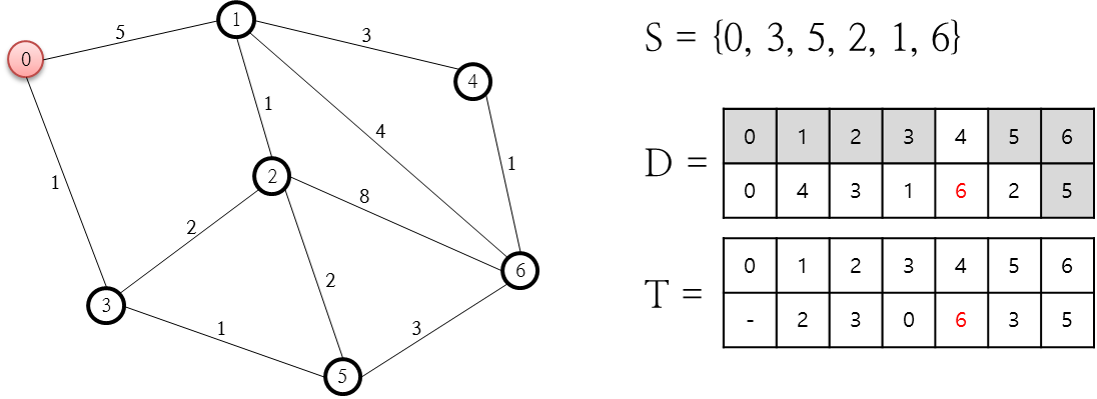
이미 처리가 완료된 노드가 아닌 것 중 최소인 노드는 6번 노드인데요. 이 6번 노드를 집합 S에 추가하고 6번 노드와 링크로 연결된 1, 2, 4, 5 중 처리가 완결되지 않은 노드는 4번인데요. 6번 노드를 경유해 4번 노드로 가기 위한 비용은 5 + 1인 6으로 계산되며, 이 값은 이전 단계에서 계산된 값(7)보다 작으므로 D 저장소가 변경되고, 이와 함께 T 저장소에 대해서도 4번 노드에 대해 6번 노드로 변경합니다. 다음 단계로 진행합니다.
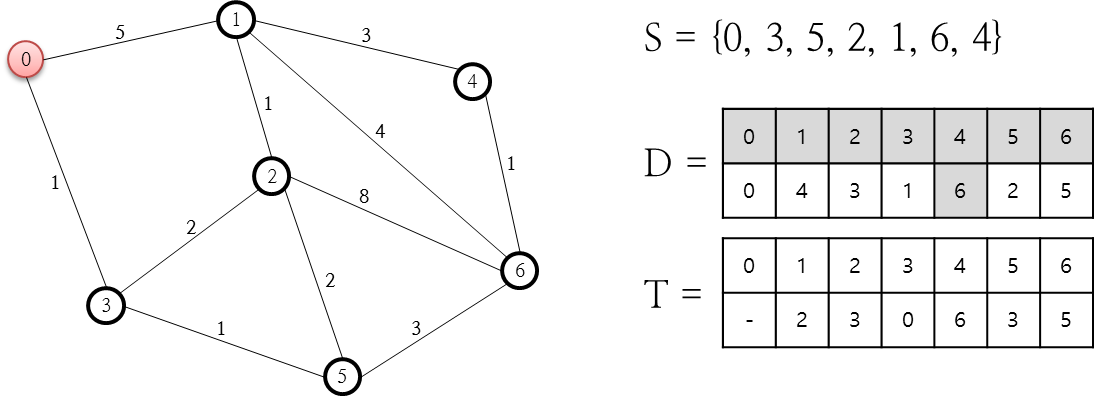
처리되지 않은 노드 중, 이제 유일하게 4번 노드만 남았는데요. 4번 노드와 연결된 1, 6번 노드에 대해 처리를 해야 하는데 이미 1, 6번 노드는 처리가 완결되었으므로 더 이상 진행하지 않고 종료됩니다.
이상의 결과에서 T 저장소를 통해 출발 노드인 0번 노드에서 각 노드에 대한 최단 경로를 파악할 수 있습니다. 0번 노드에서 1번 노드에 대한 최단 경로는 (1번 노드)←(2번 노드)←(3번 노드)←(0번 노드)가 됩니다. 이는 T 저장소를 보면, 먼저 1번 노드에 연결되는 노드는 2번 노드라는 것을 알 수 있고, 다시 2번 노드는 3번 노드와 연결되며 3번 노드는 시작 노드인 0번 노드라고 기록되어 있기 때문입니다. 시작 노드 0번에서 각 노드에 대한 최단 경로를 정리하면 다음과 같습니다.
- 0번 노드에서 1번 노드 : (1번 노드)←(2번 노드)←(3번 노드)←(0번 노드)
- 0번 노드에서 2번 노드 : (2번 노드)←(3번 노드)←(0번 노드)
- 0번 노드에서 3번 노드 : (3번 노드)←(0번 노드)
- 0번 노드에서 4번 노드 : (4번 노드)←(6번 노드)←(5번 노드)←(3번 노드)←(0번 노드)
- 0번 노드에서 5번 노드 : (5번 노드)←(3번 노드)←(0번 노드)
- 0번 노드에서 6번 노드 : (6번 노드)←(5번 노드)←(3번 노드)←(0번 노드)