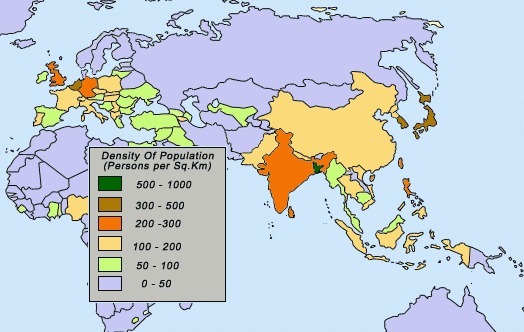
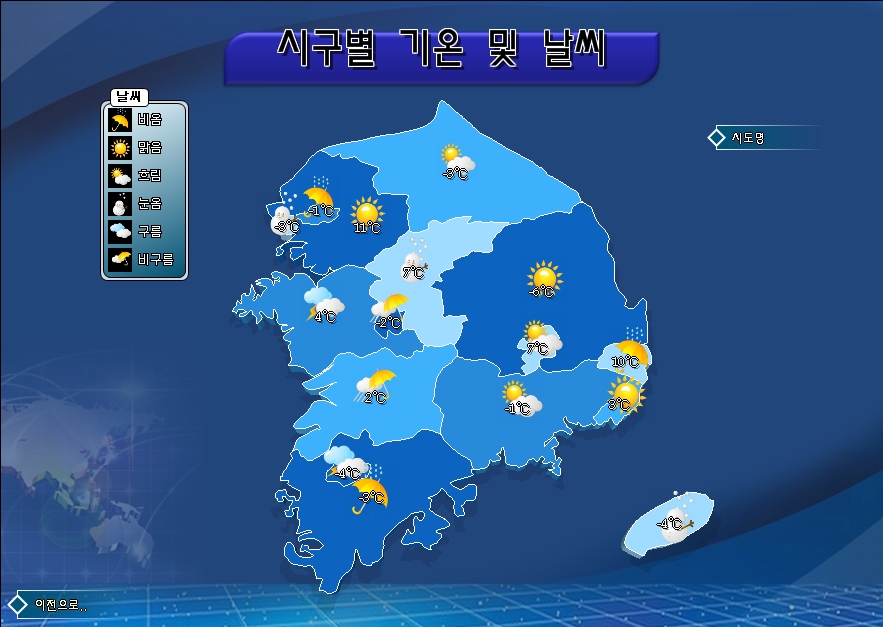
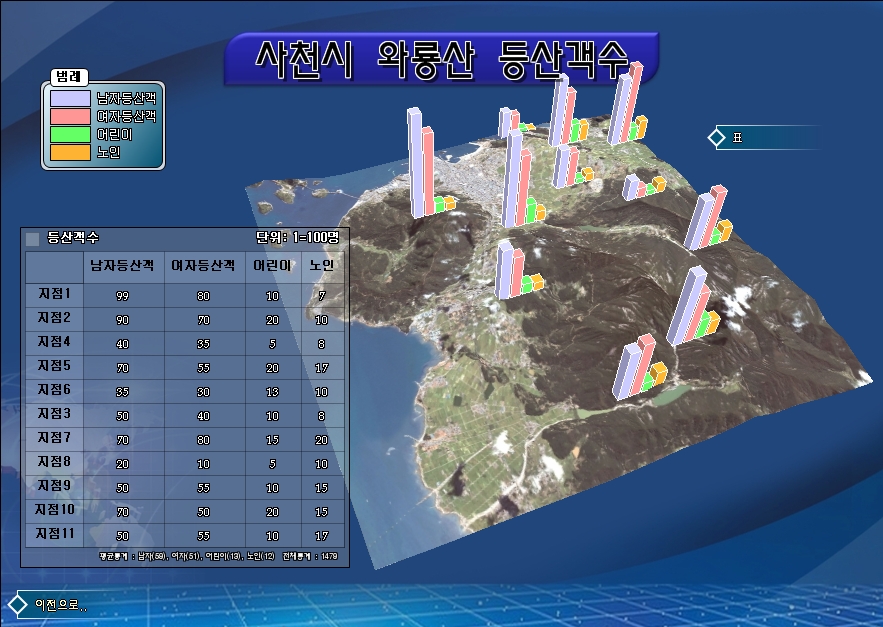
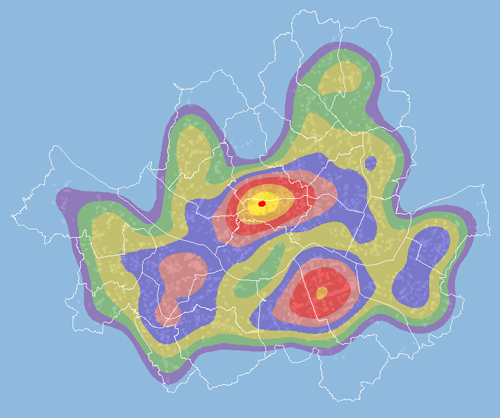
XGE에 이번에 추가한 밀도계산 기능을 ArcGIS와 비교해 보았습니다. 아래는 ArcGIS의 Simple 방식의 밀도 분석입니다. 주제는 “교육”입니다. 학교의 분포이겠지요.
참고로 XGE는 국내 최고의 비지니스 GIS 솔루션 기술을 가진 GIS 전문 회사((주)오픈메이트)가 보유한 GIS 엔진의 차기 버전입니다. XGE는 현재 개발단계인지라.. Code Name이고, 추후 멋드러진 이름을 갖게 되겠지요~ ^^
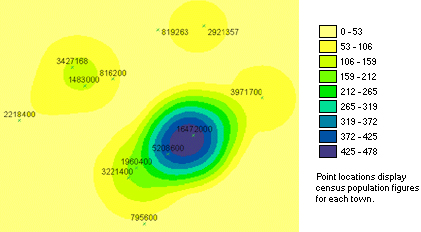
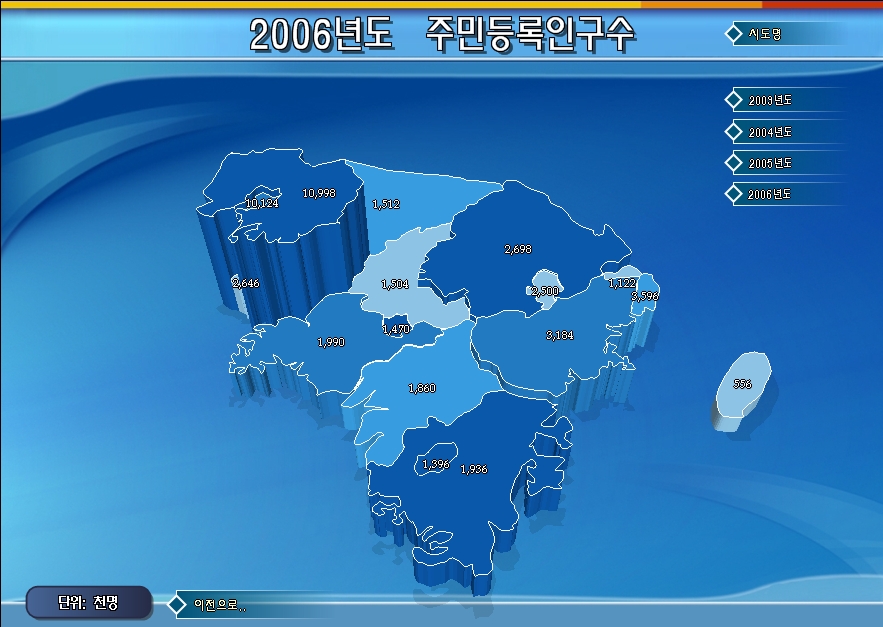
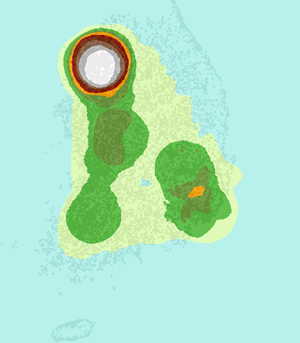 아래는 동일한 데이터.. 즉, 위에 대한 XGE의 결과입니다.
아래는 동일한 데이터.. 즉, 위에 대한 XGE의 결과입니다.
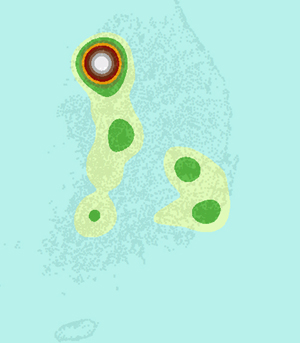
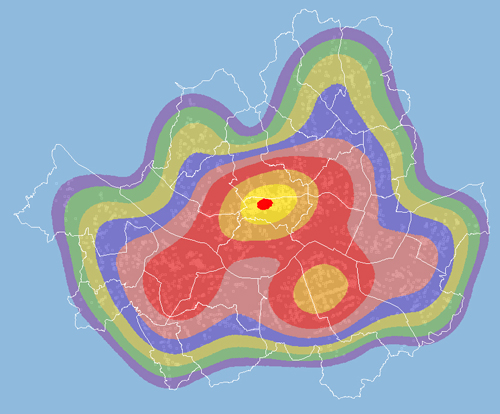
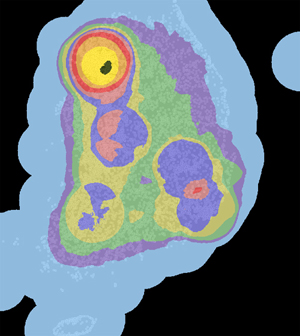 밀도 계산중 심플 방식은 속도는 매우 빠르지만, 그 결과는 그리 Nice~ 하지 않습니다. 아래는 실제 밀도 계산에서 가장 많이 쓰이는 Kernel 방식이며 ArcGIS에서 얻은 결과입니다. 심플 방식에 비해 결과가 Nice~ 하지요..
밀도 계산중 심플 방식은 속도는 매우 빠르지만, 그 결과는 그리 Nice~ 하지 않습니다. 아래는 실제 밀도 계산에서 가장 많이 쓰이는 Kernel 방식이며 ArcGIS에서 얻은 결과입니다. 심플 방식에 비해 결과가 Nice~ 하지요..
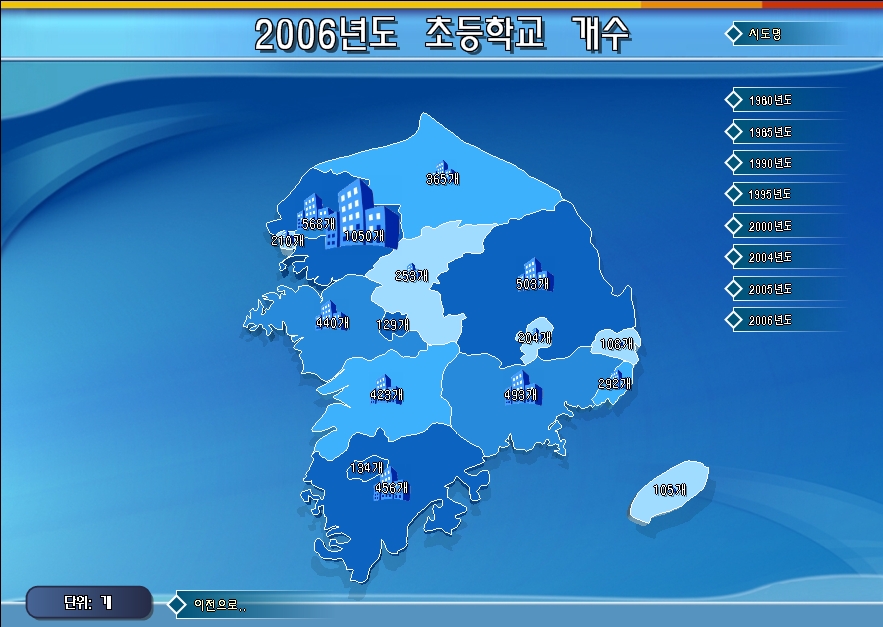
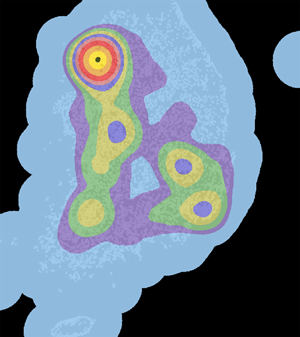
 아래는 위와 동일한 데이터와 밀도 계산을 위한 변수(셀해상도, 계산반경)에 대한 XGE의 결과입니다. 배경이 검정인 이유는 검색반경에 영향을 받지 않아 Null Value인 셀입니다. ArcGIS의 경우 이 Null Value인 셀에 대해서는 가장 낮은 값으로 할당한 색상으로 표현하고 있습니다.
아래는 위와 동일한 데이터와 밀도 계산을 위한 변수(셀해상도, 계산반경)에 대한 XGE의 결과입니다. 배경이 검정인 이유는 검색반경에 영향을 받지 않아 Null Value인 셀입니다. ArcGIS의 경우 이 Null Value인 셀에 대해서는 가장 낮은 값으로 할당한 색상으로 표현하고 있습니다.
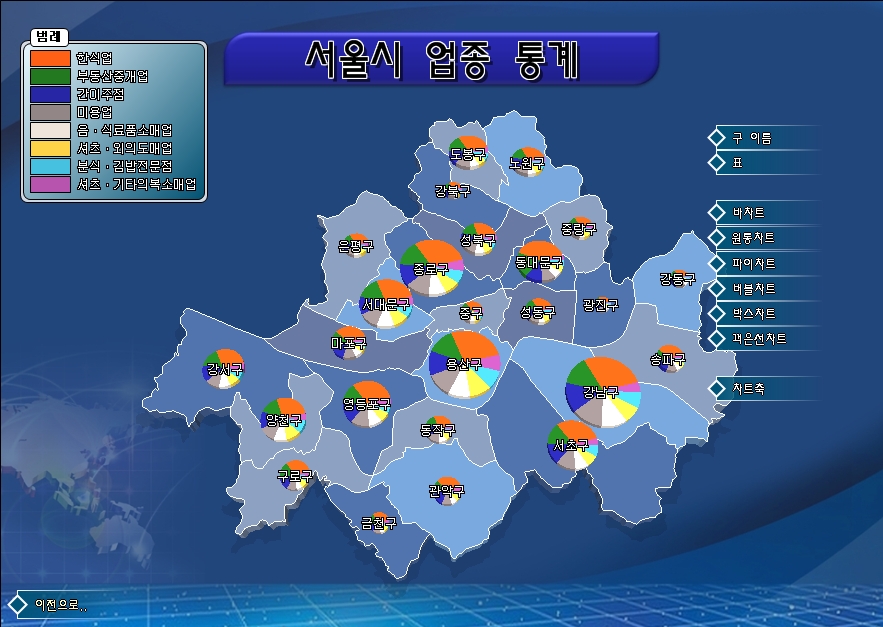
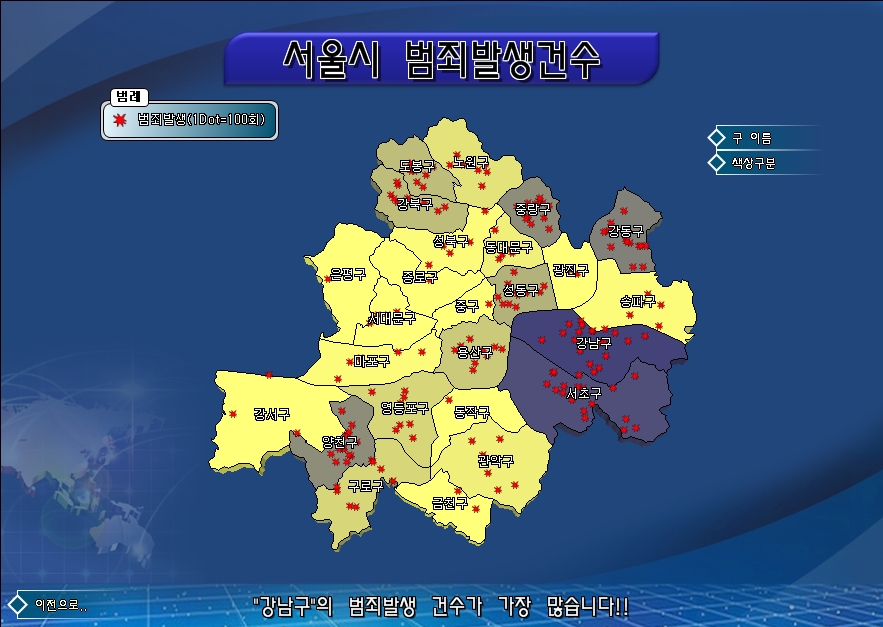
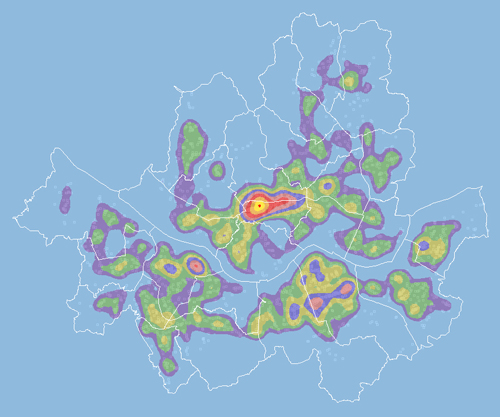
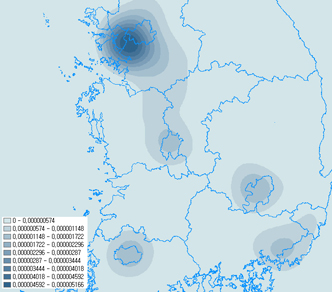
 아래는 서울 지역에 대한 은행분포를 나타낸 Kernel 방식의 밀도 계산이며 모두 XGE로 얻은 결과입니다. 감상(?) 해보시길 바랍니다. ^^ ArcGIS에서처럼 Null Value인 셀에 대해서도 최하위 단계의 색상으로 표현하고 있습니다.
아래는 서울 지역에 대한 은행분포를 나타낸 Kernel 방식의 밀도 계산이며 모두 XGE로 얻은 결과입니다. 감상(?) 해보시길 바랍니다. ^^ ArcGIS에서처럼 Null Value인 셀에 대해서도 최하위 단계의 색상으로 표현하고 있습니다.
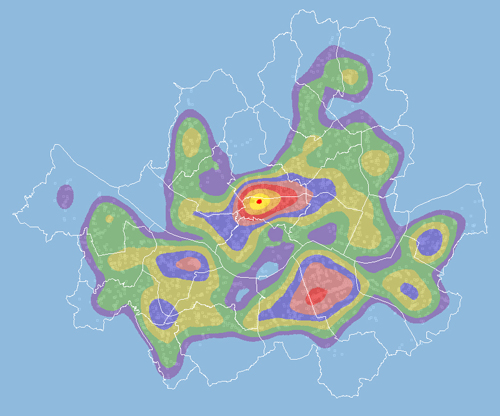
보시면 은행이 중구에 가장 많이 밀집되어있고 그 다음에 강남구 쪽에 많이 밀집되어 있다는 것을 알 수 있습니다. 밀도 분석은 2차원에서 그 분포에 대한 가중치를 구해 다양한 분석에 활용될 수 있는 조건 계산법입니다.
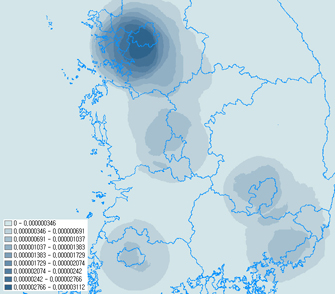 밀도 개산의 가장 많은 활용처는 포인트나 폴리라인에 대해 어느 부분에 밀집되어져 있느냐를 시각적으로 효과적으로 파악할 수 있다는 점입니다. 또한 이러한 밀도 개산에 의해 생성된 Grid 데이터를 여러개를 동시에 중첩하여 여러개의 인자들에 대한 복합적인 분석에 매우 효과적으로 활용됩니다. XGE에서는 ArcGIS의 밀도 분석은 물론이고 시각적으로 어느 부분이 가장 밀집도가 높으냐라는 판단이 아니라, 정확히 이 부분이 가장 밀집도가 높다라는 “제시”까지 제공할 예정입니다. “제시”는 기본이 되는 밀도개산 기능이 잘 완료가 되면 쉽게 구현할것으로 판단됩니다.
밀도 개산의 가장 많은 활용처는 포인트나 폴리라인에 대해 어느 부분에 밀집되어져 있느냐를 시각적으로 효과적으로 파악할 수 있다는 점입니다. 또한 이러한 밀도 개산에 의해 생성된 Grid 데이터를 여러개를 동시에 중첩하여 여러개의 인자들에 대한 복합적인 분석에 매우 효과적으로 활용됩니다. XGE에서는 ArcGIS의 밀도 분석은 물론이고 시각적으로 어느 부분이 가장 밀집도가 높으냐라는 판단이 아니라, 정확히 이 부분이 가장 밀집도가 높다라는 “제시”까지 제공할 예정입니다. “제시”는 기본이 되는 밀도개산 기능이 잘 완료가 되면 쉽게 구현할것으로 판단됩니다.