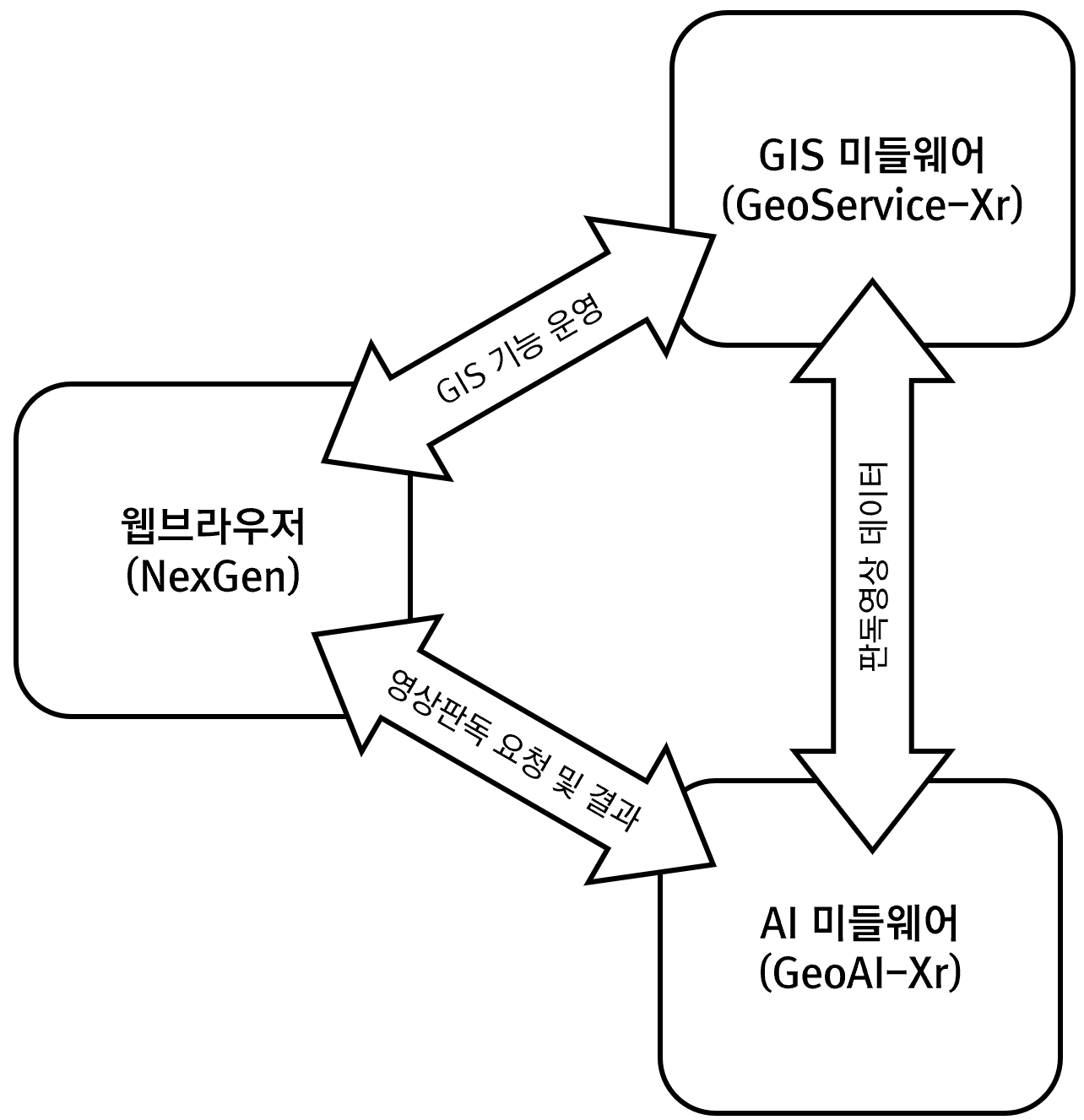
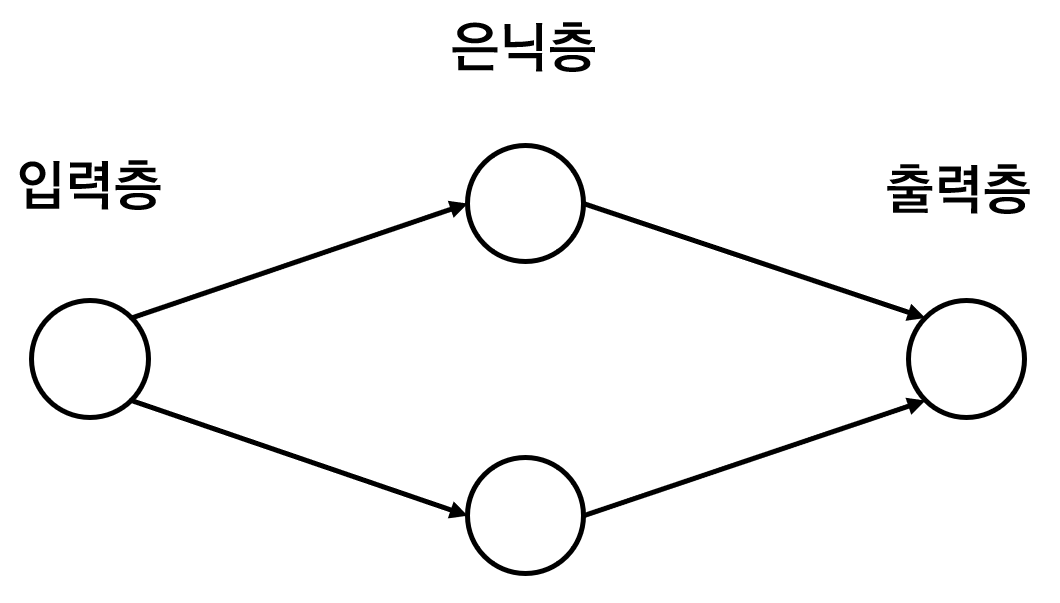
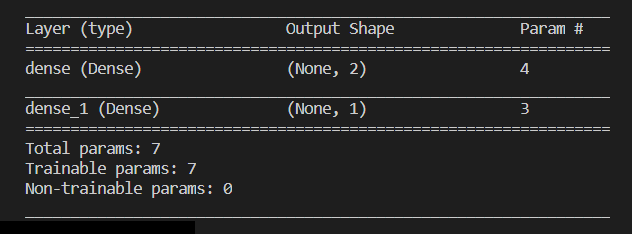
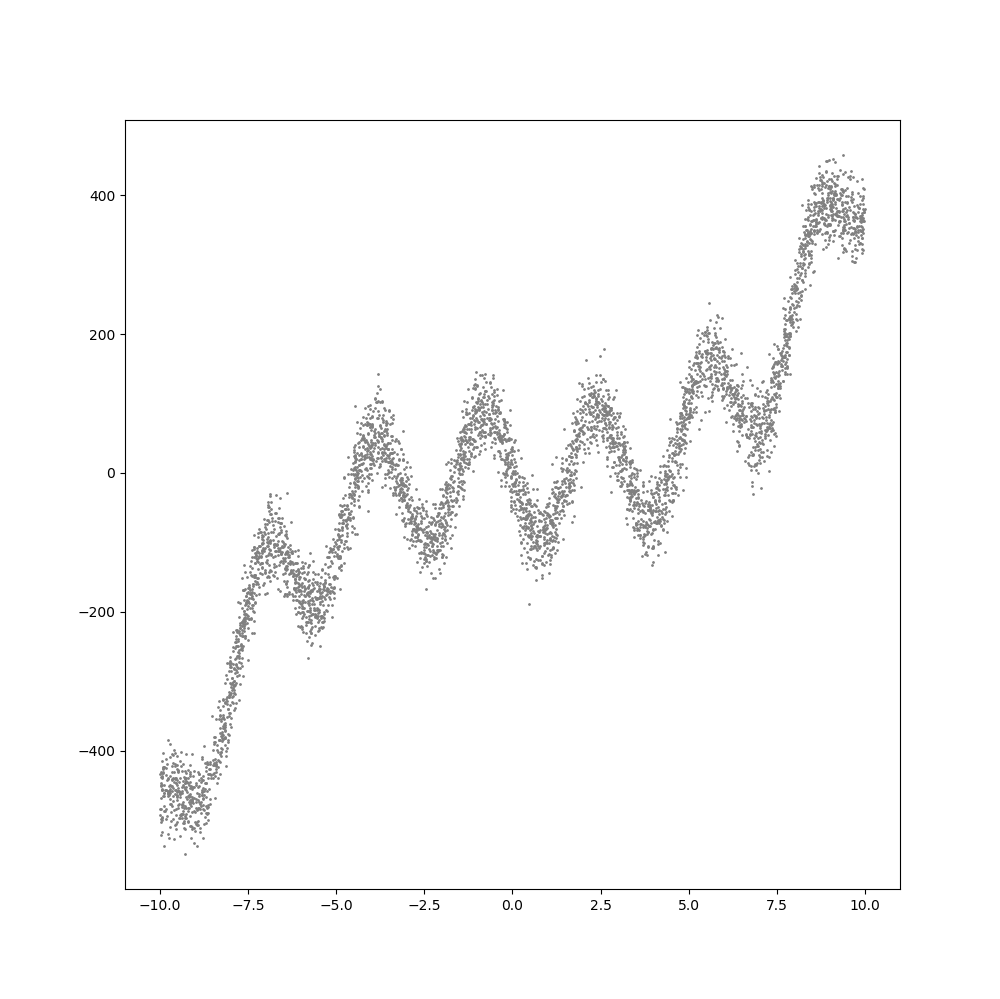
다음과 같은 구조의 신경망을 구현에 대한 내용이다.
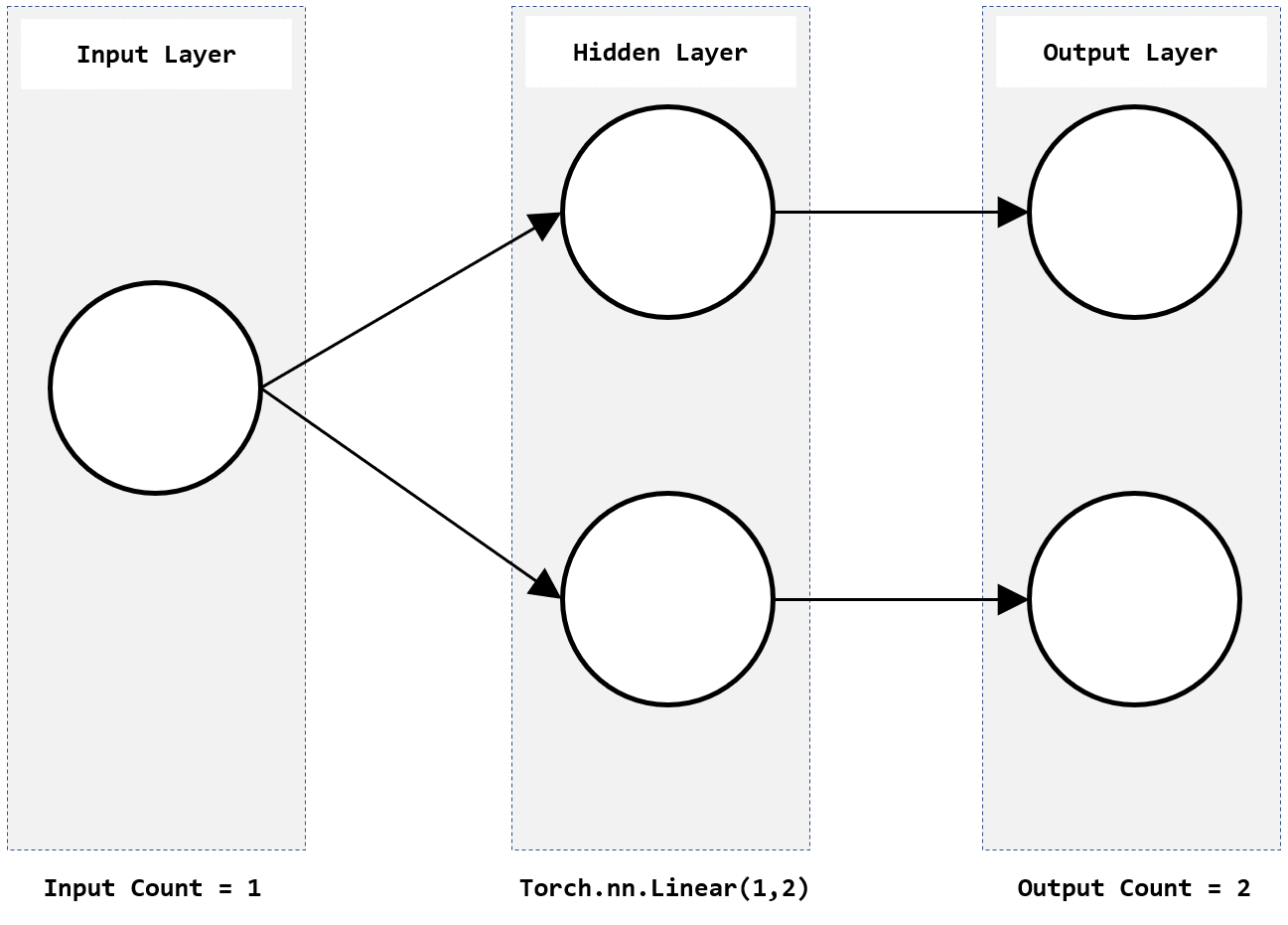
위의 신경망을 통해 판단할 수 있는 것은 입력값은 1개이고 출력값이 2개이므로 각각의 텐서구조는 [x], [y1, y2]라는 것이다. 신경망의 마지막 은닉층의 뉴런개수는 출력 개수와 동일하므로 2개이다.
코드를 보자. 먼저 필요한 패키지의 임포트이다. 파이토치를 사용한 예이다.
import torch import torch.nn as nn import torch.optim as optim import torch.nn.init as init
데이터를 준비한다.
num_data = 4000 x = torch.Tensor(num_data,1) init.uniform_(x,-10,10) noise = torch.FloatTensor(num_data,2) init.normal_(noise, std=1) def func1(x): return 4*x+5 def func2(x): return 7*x+3 y1 = func1(x) y2 = func2(x) y_noise = torch.Tensor(num_data,2) y_noise[:,0] = y1[:,0] + noise[:,0] y_noise[:,1] = y2[:,0] + noise[:,1]
데이터셋의 구성 개수는 4000개로 했다. 입력값(x)에 대해 2개의 출력값을 위한 선형공식이 9와 10 라인에 보인다. 12-17라인은 데이터에 잡음을 추가한 것이다. 잡음이 추가된 데이터를 통해 가중치(기울기)인 4, 7과 편향(y절편)인 5, 3을 결과를 얻어내면 된다. 아래는 이를 위한 학습 코드다.
model = nn.Linear(1,2)
loss_func = nn.L1Loss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
label = y_noise
num_epoch = 2000
for i in range(num_epoch):
optimizer.zero_grad()
output = model(x)
loss = loss_func(output, label)
loss.backward()
optimizer.step()
if i%10 == 0:
print(loss.data)
param_list = list(model.parameters())
print(param_list[0], param_list[1])
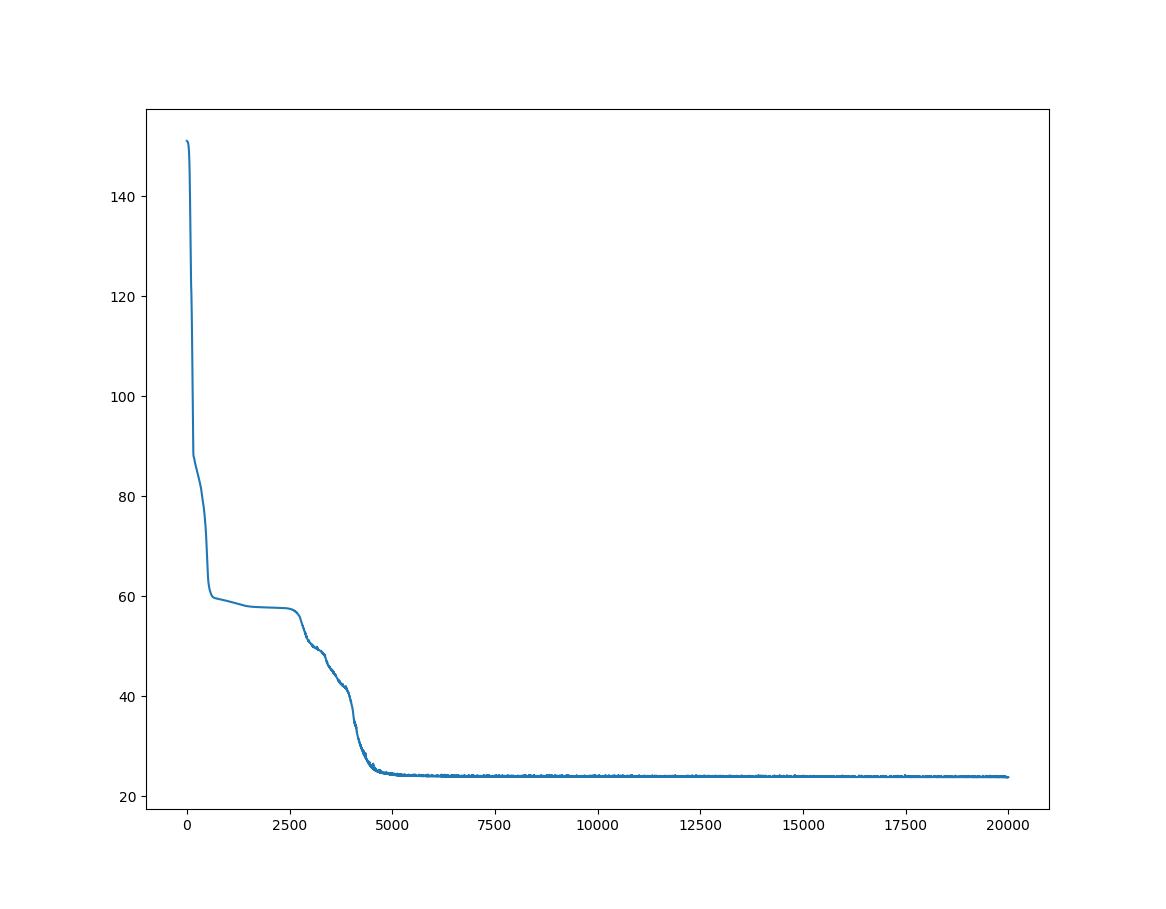
결과는 다음과 같다.
tensor(28.9745)
tensor(27.7681)
tensor(26.5639)
tensor(25.3614)
tensor(24.1623)
tensor(22.9677)
tensor(21.7777)
.
.
.
tensor(0.7945)
tensor(0.7945)
tensor(0.7945)
Parameter containing:
tensor([[3.9986],
[7.0006]], requires_grad=True) Parameter containing:
tensor([4.9845, 3.0214], requires_grad=True)
총 2000번 학습 시켰고, 그 결과로 손실값이 약 27로 시작해서 약 0.79 줄었다. 그리고 결과는 4, 7 그리고 5, 3에 근사한 값이 나온것을 알 수 있다.
이 코드를 통해 알아낸 것은 1개의 특성을 통해 그보다 더 많은 2개의 특성을 얻어내야 하는 이 경우에는 입력 데이터가 상대적으로 많아야 한다는 것이다. 이 경우는 4000개이다. 아울러 적당한 손실함수를 사용해야 한다. 위의 예제는 L1 손실함수를 사용했지만 평균제곱오차 손실함수를 사용하면 더 적은 데이터(이 부분은 확인이 필요함)와 반복학습이 가능하다.
여기서 입력 데이터와 분석 결과를 그래프로 시각화 해보자. 해당 코드는 아래와 같다. 지금까지의 코드에서 마지막에 붙이면 된다.
import matplotlib.pyplot as plt import numpy as np plt.figure(figsize=(15,15)) plt.scatter(x.numpy(),y_noise[:,0].numpy(),s=3,c="gray") plt.scatter(x.numpy(),y_noise[:,1].numpy(),s=3,c="black") x = np.arange(-10, 10, 0.01) plt.plot(x, func1(x), linestyle='-', label="func1", c='red') plt.plot(x, func2(x), linestyle='-', label="func2", c='blue') plt.axis([-10, 10, -30, 30]) plt.show()
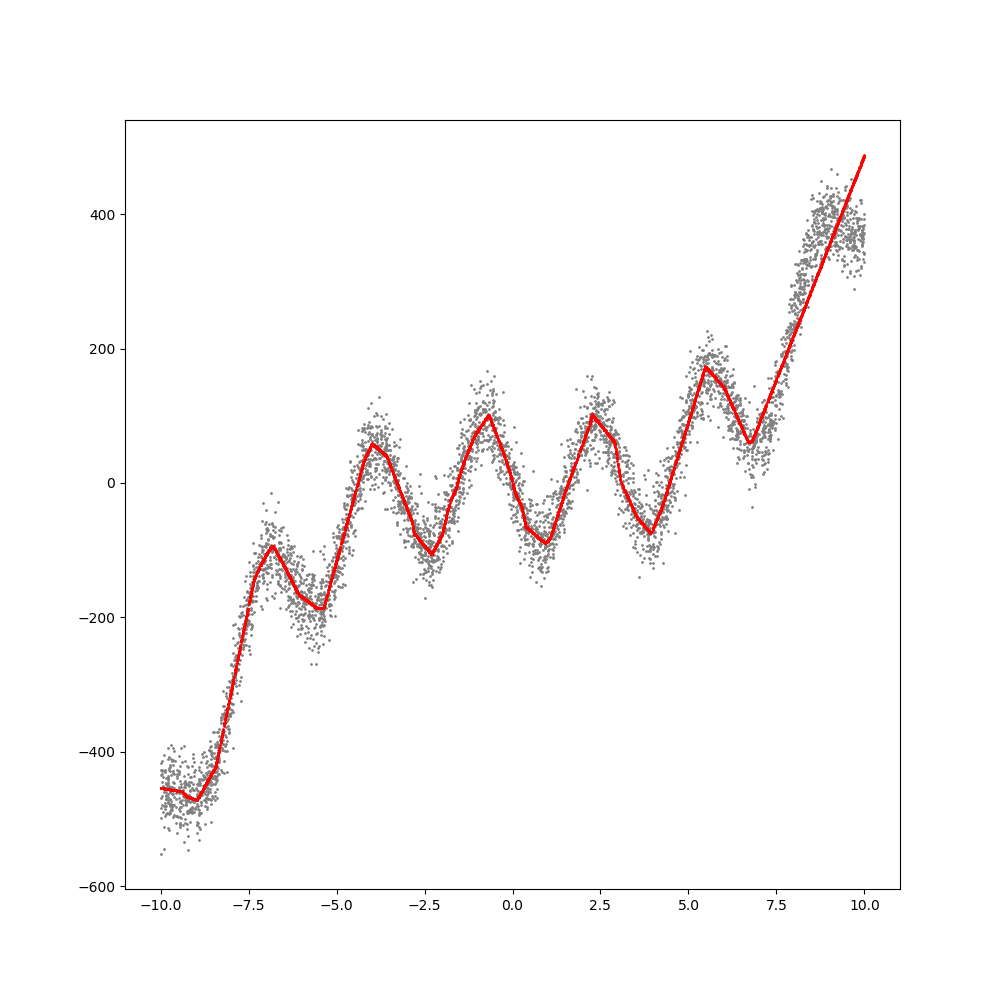
그래프는 다음과 같다.
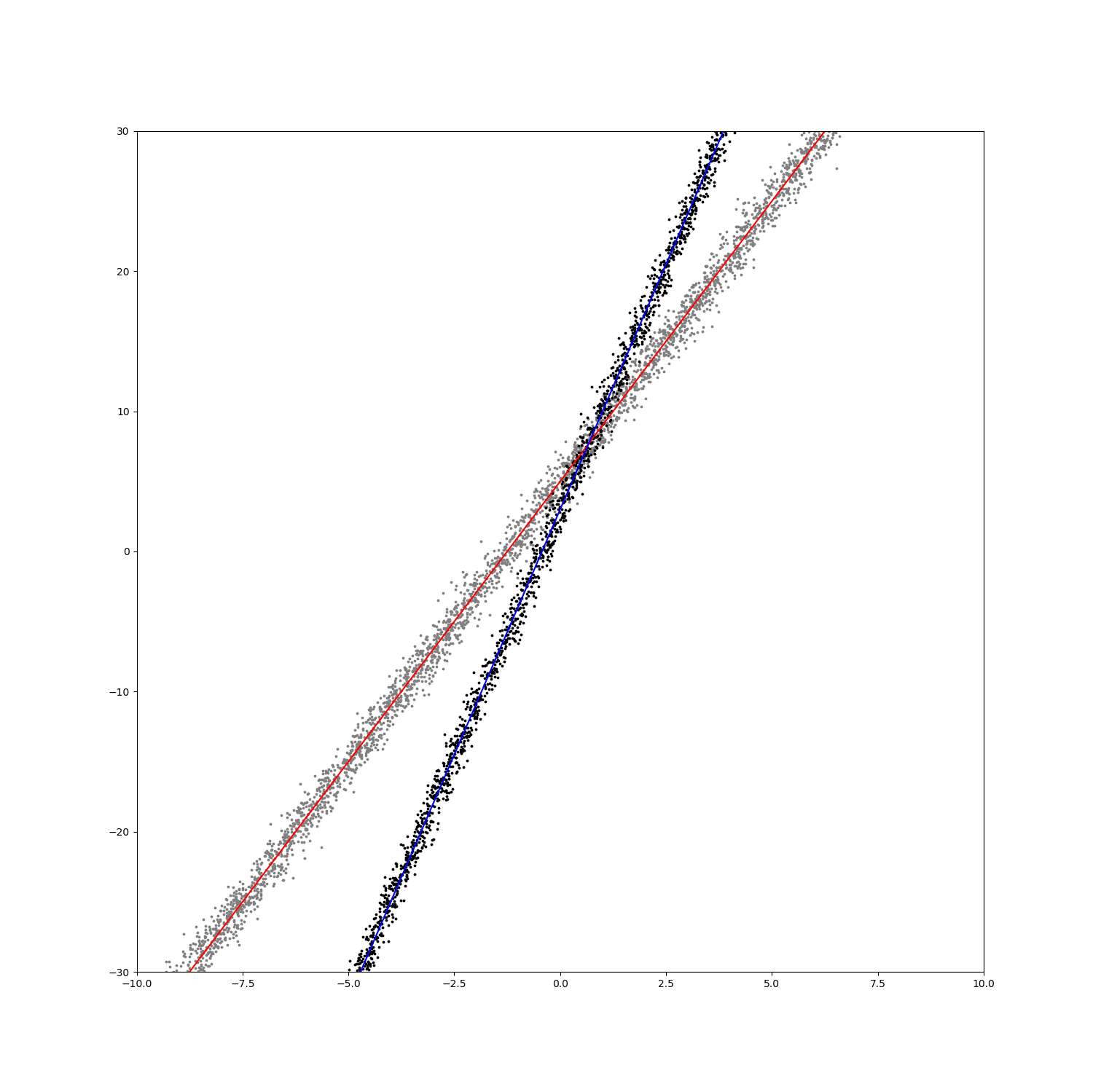
회색점과 검정색점은 입력 데이터이고, 빨간색선과 파란색선은 선형회귀 결과를 표시한 것이다.