잡음이 섞인 샘플 데이터가 선형이라고 가정할때, 이 선형 모델은 기울기와 절편이라는 값으로 정의됩니다. 이 기울기와 절펀에 대한 값을 구하는 방법은 다양한데, 이 글에서는 2가지 접근 방법을 언급합니다. 먼저 잡음이 섞인 샘플 데이터는 다음과 같습니다.
import numpy as np import matplotlib.pyplot as plt X = 10 * np.random.rand(100,1) y = 3.7 - 2.5 * X + np.random.randn(100,1) plt.scatter(X, y) plt.show()
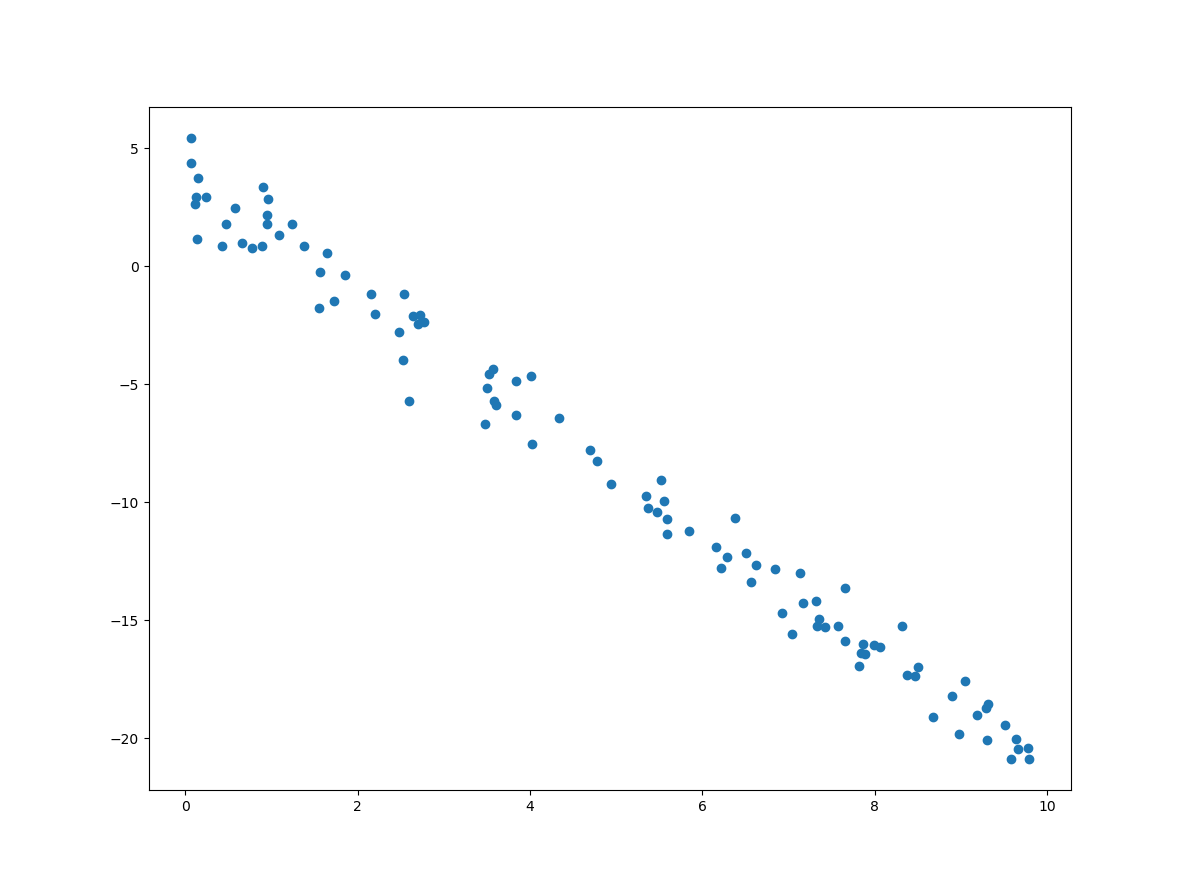
위의 코드는 샘플 데이터에 대한 시각화 코드도 포함하고 있는데, 그 결과는 다음과 같습니다.
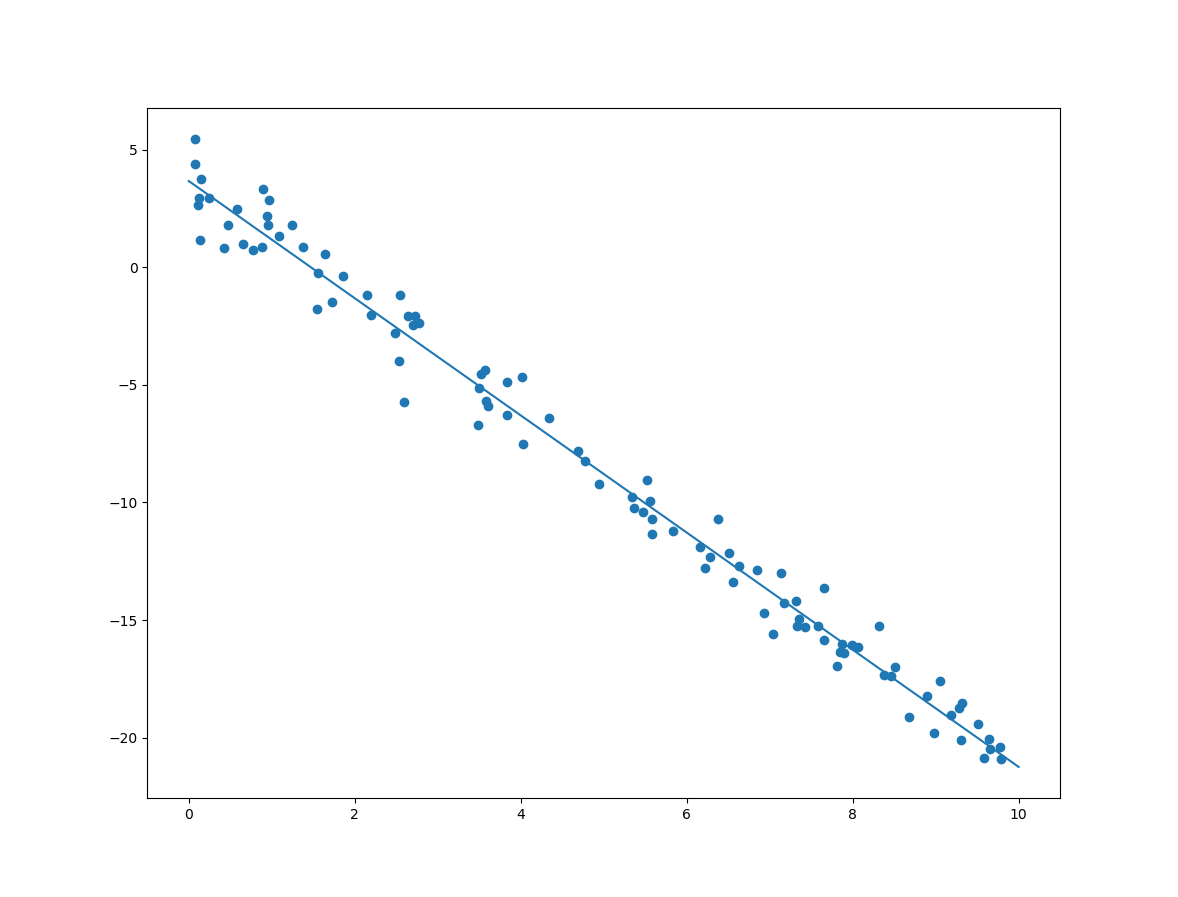
이제 위의 샘플 데이터에 대한 선형회귀 방법 중 하나인 정규방정식(Normal Equation)에 대한 코드는 다음과 같습니다.
X_b = np.c_[np.ones((100,1)), X] w = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y) print(w) plt.scatter(X, y) drawLine(w[1], w[0]) plt.show()
분석된 절편과 기울기에 대한 출력 및 결과 모델의 선형은 다음과 같습니다.
[[ 3.76686801] [-2.50677558]]
아울러 정규방정식은 다음과 같습니다.

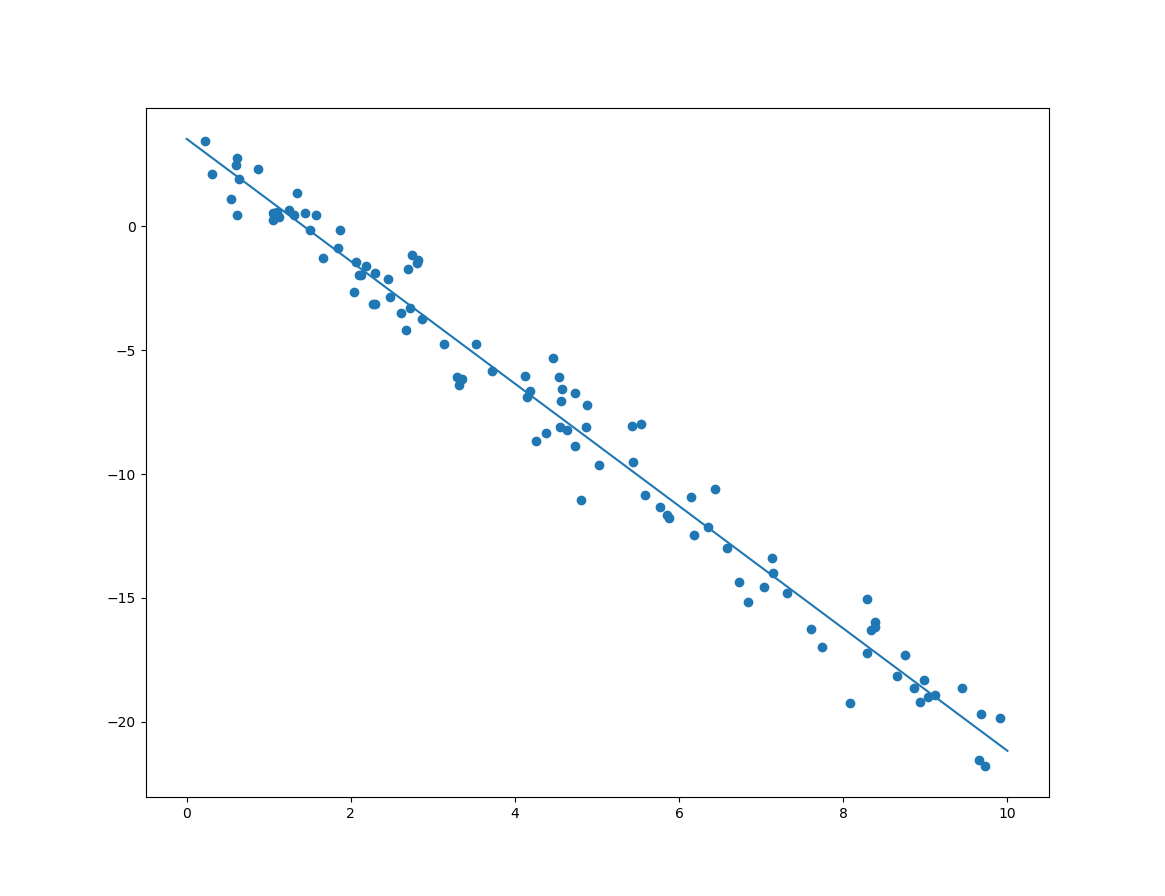
다음은 사이킷런에서 제공하는 LinearRegression 클래스를 이용한 방법입니다.
from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X, y) w = [model.intercept_[0], model.coef_[0][0]] print(w) plt.scatter(X, y) drawLine(w[1], w[0]) plt.show()
분석된 절편과 기울기에 대한 출력 및 결과 모델의 선형은 다음과 같습니다.
[[ 3.69686801] [-2.50677558]]
위의 코드에서 절편과 기울기를 통해 그래프를 그리는 함수인 drawLine은 다음과 같습니다.
def drawLine(m, b):
X = np.arange(0, 11)
y = [m * x + b for x in X]
plt.plot(X, y)