이 글의 원문은 https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_houghlines/py_houghlines.html#hough-lines 입니다.
이미지에서 선 모양의 도형을 검출하는 Hough Transform에 대해 살펴보고, 이 알고리즘을 구현한 OpenCV의 함수를 살펴봅니다.
먼저 Hough Transfom은 이미지에서 수학적으로 표현 가능한 도형을 검색하는 기술입니다. 그 도형 중 선형에 대해 검색해 볼텐데요. 선에 대한 방정식은 우리가 흔히 알고 있는 기울기(m)와 y절편(c)로 표현되는 𝑦=m𝑥+c도 있지만 삼각함수에 의한 매개변수 방정식으로써는 r = 𝑥cos𝜃 + 𝑦sin𝜃 로도 표현됩니다.
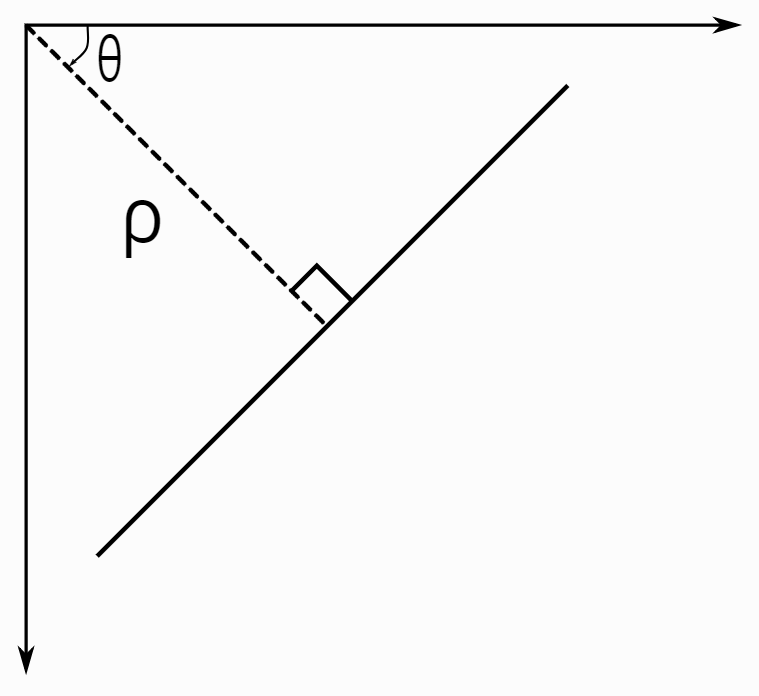
r는 원점으로부터 직선까지의 수직거리이고, 𝜃는 수직선으로부터 x축까지의 반시계방향 각도입니다. 이 선에 대한 모델은 (r, 𝜃)로 표현되고, 이를 2차원 배열에 맵핑하는 것을 생각해 볼 수 있습니다. 즉, 2차원 배열의 열(row)가 r이고 행(column)이 𝜃로 정합니다. 거리 r과 각도 𝜃에 대한 정밀도를 고려하지 않으면 배열의 크기는 무한대가 됩니다. 그래서 r은 이미지의 대각 크기로 하며 단위는 1로 합니다. 이미지는 픽셀로 구분되니까요. 그리고 𝜃는 0-180의 범위로 하고 단위는 1로 합니다. 𝜃를 0-180로 하면 어떠한 선도 표현 가능하고, 단위를 1로 한다는 것은 회전된 선을 총 180개로만 표현 가능하다는 것입니다. 즉, 1도 단위는 정밀도의 단위입니다. 이제, 100×100 크기의 이미지에 시작점(30,50)과 끝점(70,50)으로 연결된 선에 대해 Hough Transfrom 알고리즘을 고려해 보겠습니다. 이 선을 구성하는 모든 픽셀들을 고려하는 것이 맞겠으나, 여기서는 편의상 시작점과 끝점만을 고려해 보겠습니다. r = 𝑥cos𝜃 + 𝑦sin𝜃 식에 대해서 (𝑥, 𝑦)가 (30, 50)인 𝜃는 모든 0-180까지에 대해 r을 구하고 구해진 (r, 𝜃)에 해당하는 배열 요소의 값을 1 증가시킵니다. 물론 초기 배열의 모든 항목은 0으로 초기화되어 있겠지요. 그 다음에 다시 (𝑥, 𝑦)가 (70, 50)인 𝜃는 모든 0-180까지에 대해 r을 구하고 구해진 (r, 𝜃)에 해당하는 배열 요소의 값을 1 증가시킵니다. 결과적으로 배열의 항목 중 가장 큰 값을 찾아 보면 r=50, 𝜃=90이 되고 이미지에서 선에 대한 매개변수 정의의 값과 일치합니다.
이제 이 Hough Transform을 OpenCV에서 구현한 예제를 살펴 보겠습니다.
import cv2
import numpy as np
img = cv2.imread('./data/dave.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,50,150,apertureSize = 3)
lines = cv2.HoughLines(edges,1,np.pi/180,150)
for line in lines:
rho,theta = line[0]
a = np.cos(theta)
b = np.sin(theta)
x0 = a*rho
y0 = b*rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv2.line(img,(x1,y1),(x2,y2),(0,0,255),1)
cv2.imshow('edges', edges)
cv2.imshow('result', img)
cv2.waitKey()
cv2.destroyAllWindows()
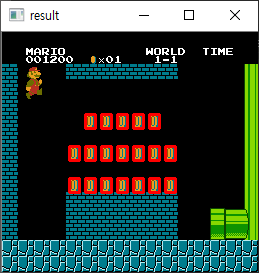
실제 칼러 영상에 대해 바로 Hough Transform를 적용하기에는 너무 복잡해서 먼저 Gray 영상으로 변환하고 경계선을 추출한 뒤에 Hough Transform를 적용합니다. Hough Transform를 적용하는 코드가 8번인데, cv2.HoughLines 함수의 인자는 살펴보면, 첫번째는 입력 이미지, 두번째는 r의 정밀도(1로 지정했으며 1픽셀 단위), 세번째는 𝜃의 정밀도(1도로 지정했으며 라이언 단위), 네번째는 앞서 언급한 (r, 𝜃)에 해당하는 배열 요소에 저장된 값 중 네번째 인자로 지정된 값 이상인 것만을 추출하기 위한 조건값입니다.
실행해 보면 결과는 다음과 같습니다.
![]()
앞서 살펴본 Hough Transform 알고리즘은 선을 구성하는 모든 픽셀에 대해 2차원 배열 항목에 대한 값 처리를 수행하고 있어 퍼포먼스가 제법 떨어집니다. 이에 대해서 모든 픽셀 값을 처리하지 않고 적당히 필요한 만큼 확률적으로 픽셀들을 선택해 연산하는 방법(Probabilistic Hough Transform)이 있는데, 그 예가 아래와 같습니다.
import cv2
import numpy as np
img = cv2.imread('./data/dave.jpg')
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,50,150,apertureSize = 3)
minLineLength = 50
maxLineGap = 10
lines = cv2.HoughLinesP(edges,1,np.pi/180,100,minLineLength,maxLineGap)
for line in lines:
x1,y1,x2,y2 = line[0]
cv2.line(img,(x1,y1),(x2,y2),(0,255,0),1)
cv2.imshow('edges', edges)
cv2.imshow('result', img)
cv2.waitKey()
cv2.destroyAllWindows()
10번 코드의 cv2.HoughLinesP 함수가 바로 Probabilistic Hough Transform 방법을 사용하는데, 기존의 cv2.HoughLines 함수와 4개의 인자는 동일하지만 추가적으로 2개 인자가 지정되어 있습니다. 첫번째는 minLineLength로 검출된 선의 길이가 이 인자값보다 작으면 선이 아니라는 조건값이고, 두번째는 maxLineGap로 2개의 선 사이의 거리가 이 값보다 작다면 하나의 선으로 인식하라는 조건값입니다. 결과는 다음과 같습니다.
![]()