이 글의 원문은 https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_video/py_meanshift/py_meanshift.html 입니다.
비디오의 연속된 이미지에서 동일한 객체를 찾고 추적하는 알고리즘인 Meanshift와 Camshift에 대한 내용입니다. Meanshift는 매우 직관적입니다. 어떤 포인트의 집합을 가지고 있다고 합시다. (이 포인트의 집합은 Histogram Backprojection과 같은 픽셀들의 분포라고도 할 수 있음) 아래 그림처럼 원 모양의 작은 윈도우가 있고, 이 윈도우를 최대 픽셀 밀도값(또는 포인트의 최대 개수)을 가지는 영역으로 이동합니다. 아래 그림처럼 말입니다.
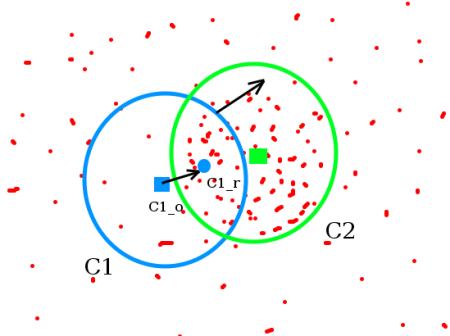
초기 윈도우는 파란색의 원이며 C1이라고 합시다. 이 C1의 원래 중심점은 파란색 사각형으로 표시되어 있고 C1_o라고 합시다. 그러나 만약 이 윈도우에 포함된 포인트들의 무게중심점을 구해보면, C1_o과 위치가 다르고C1_r가 됩니다. 이제 파란색 원의 중심점을 c1_r로 이동하고 이동된 윈도우에 포함된 포인트의 무게중심점을 구해 원의 중심점과 동일하지 않다면 다시 원의 중심을 새롭게 구한 무게중심점으로 이동시키기를 반복합니다. 이렇게 반복하다가 원의 중심점과 윈에 포함된 포인트의 무게 중심점 위치가 동일할때 반복을 멈춥니다. 바로 이 최종적으로 얻은 원, 즉 윈도우가 최대 픽셀 분포를 가지게 됩니다. 이를 위의 그림에서 초록색 원으로 표시하고 C2라고 합시다. 위의 그림에서 보듯 이 윈도우가 가장 많은 개수의 포인트를 포함하고 있습니다. 그렇다면 이미지에서는 이러한 처리가 어떻게 진행될까요? 아래 그림과 같습니다.

통상 Histogram Backprojection된 이미지와 초기 대상 위치를 전달합니다. 객체가 이동하면, 분명히 그 움직임은 Histogram Backprojection된 이미지에 반영됩니다. 결과적으로, Meanshift 알고리즘은 최대 강도를 가지는 새로운 위치로 윈도우를 이동시키게 됩니다.
위의 Meanshift 알고리즘을 OpenCV에서 사용해 보겠습니다. 먼저 추적할 객체 대상을 설정하고 이 대상의 히스토그램을 얻는데, 이는 Meanshift 연산을 위한 동영상의 각 프레임 이미지에 이 대상을 Backprojection 하기위함입니다. 또한 윈도우의 초기 위치를 제공할 필요가 있습니다. 히스토그램을 위해 오직 HSV 중 Hue 값만을 고려합니다. 또한 가짜 값들을 피하기 위해 cv2.inRange() 함수를 사용해 어두운 부분을 제거합니다. 전체 예제는 다음과 같습니다.
import numpy as np
import cv2
cap = cv2.VideoCapture('slow.flv')
# take first frame of the video
ret,frame = cap.read()
# setup initial location of window
r,h,c,w = 250,90,400,125 # simply hardcoded the values
track_window = (c,r,w,h)
# set up the ROI for tracking
roi = frame[r:r+h, c:c+w]
hsv_roi = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv2.normalize(roi_hist,roi_hist,0,255,cv2.NORM_MINMAX)
# Setup the termination criteria, either 10 iteration or move by atleast 1 pt
term_crit = ( cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret ,frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# apply meanshift to get the new location
ret, track_window = cv2.meanShift(dst, track_window, term_crit)
# Draw it on image
x,y,w,h = track_window
img2 = cv2.rectangle(frame, (x,y), (x+w,y+h), 255,2)
cv2.imshow('img2',img2)
k = cv2.waitKey(60) & 0xff
if k == 27:
break
else:
cv2.imwrite(chr(k)+".jpg",img2)
else:
break
cv2.destroyAllWindows()
cap.release()
실행해 보면, 지정한 부분(10번 코드의 사각영역)에 대한 객체를 동영상에서 추적하기 시작합니다. 아래는 동영상 중 3개의 프레임 결과 이미지입니다.

다음은 Camshift 알고리즘을 이용한 동영상에서의 객체 추적입니다. 앞서 Meanshift의 실행 결과를 보면, 객체가 점점 커지고 있음에도 윈도우의 크기는 변하지 못하고 일정합니다. Camshift 알고리즘은 이를 개선한 형태입니다. CAMshift는 Continuously Adaptive Meanshift의 약자입니다. Camshift 알고리즘은 먼저 meanshift를 적용하고, 윈도우의 크기를 다음 공식에 의해 갱신합니다.
![]()
또한 이 윈도우에 가장 잘 맞는 타원을 계산합니다. 다시 새롭게 크기가 조정된 윈도우와 이전 윈도우의 위치를 가지고 Meanshift를 적용합니다. 이러한 과정은 원하는 정확도가 나올때까지 반복합니다.
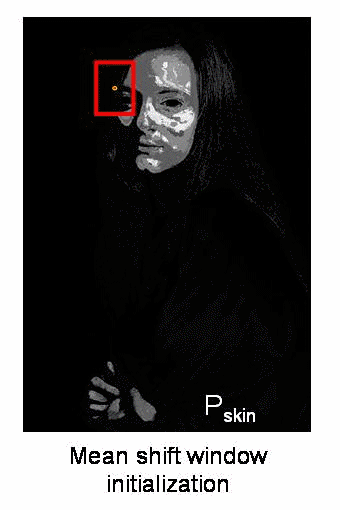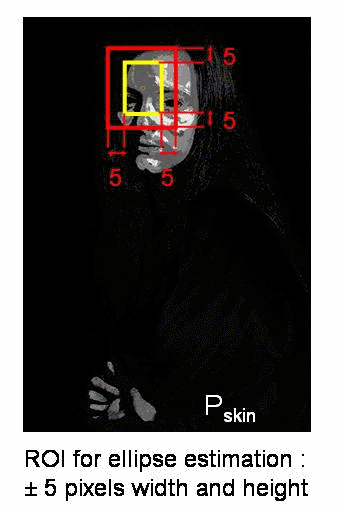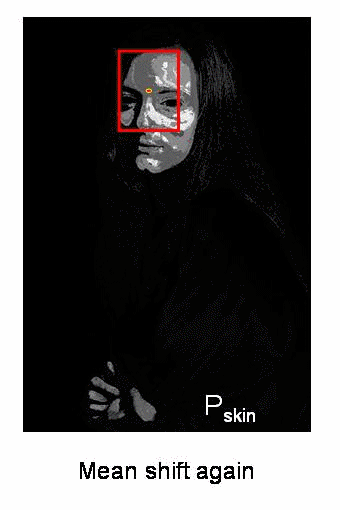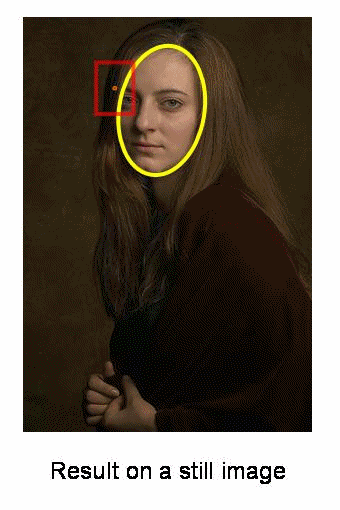
OpenCV에서 Camshift에 대한 예제를 살펴보겠습니다. 예제는 Meanshift와 유사하지만, 회전된 사각형 영역이 반환된다는 점이 다릅니다. 이렇게 반환된 사각형 영역은 다음 반복에서 검색 윈도우로 사용됩니다.
import numpy as np
import cv2
cap = cv2.VideoCapture('slow.flv')
# take first frame of the video
ret,frame = cap.read()
# setup initial location of window
r,h,c,w = 250,90,400,125 # simply hardcoded the values
track_window = (c,r,w,h)
# set up the ROI for tracking
roi = frame[r:r+h, c:c+w]
hsv_roi = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi],[0],mask,[180],[0,180])
cv2.normalize(roi_hist,roi_hist,0,255,cv2.NORM_MINMAX)
# Setup the termination criteria, either 10 iteration or move by atleast 1 pt
term_crit = ( cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 10, 1 )
while(1):
ret ,frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv],[0],roi_hist,[0,180],1)
# apply meanshift to get the new location
ret, track_window = cv2.CamShift(dst, track_window, term_crit)
# Draw it on image
pts = cv2.boxPoints(ret)
pts = np.int0(pts)
img2 = cv2.polylines(frame,[pts],True, 255,2)
cv2.imshow('img2',img2)
k = cv2.waitKey(60) & 0xff
if k == 27:
break
else:
cv2.imwrite(chr(k)+".jpg",img2)
else:
break
cv2.destroyAllWindows()
cap.release()
아래는 결과 중 3개의 프레임 이미지입니다.

추적 대상이 되는 영역이 커질 때 검색 결과 창도 같이 커지는 것을 확인할 수 있습니다.