
VS2005에서 새로운 프로젝트 창에 ISAPI 프로젝트 항목이 제외되었습니다. 게다가 VS2008에는 그나마 있던 VC++로 개발가능한 WebService 프로젝트 항목도 빠져버렸습니다. 그렇다고 해서 완전이 빠진것은 아니고 새로운 프로젝트 창에서만 제외되었고, 기존의 프로젝트를 열어서 VS2005와 VS2008에서 작업이 가능합니다. 그렇다면 새로운 프로젝트로 ISAPI 개발을 VS2005 이상에서는 시작할 수 있을까요? ISAPI를 이용한 웹컴포넌트 개발이 비록 시대에 역행하는 행위이기는 하지만 어찌되었든 MS 플렛폼인 IIS 서버 웹기반의 서비스 기술로써 가장 퍼포먼스가 뛰어나므로, 아직 폐기 시키기에는 다소 아깝지 않나 하는 생각이 듭니다.
사실 처음에는 ISAPI를 쓰지 않고 대세인 XML 기반인 웹서비스를 사용하려고 하였습니다. 그 배경은 0.2 메가 정도되는 바이너리 데이터를 웹을 통해 주고 받아야합니다. 문제는 0.2메가 크기의 바이너리 데이터를 웹서비스가 사용하는 XML로 인코딩시킬 경우의 문제점입니다.
- 원본 크기가 최대 4배까지 커진다.
- 인코딩과 디코딩하는데 걸리는 시간이 매우 길다.
자세한 내용은 이 블로그의 웹서비스와 퍼포먼스(http://www.gisdeveloper.co.kr/entry/웹서비스와-퍼포먼스)를 참고해보시길 바랍니다. 이런 문제점으로 인해 ISAPI를 이용한 서버기술로 회귀하게 되었는데…. 문제는 Visual Studio 2005와 2008에서는 이 프로젝트가 눈에 보이지 않는다는 것입니다. 다행인것은 아예 제거된것이 아닙니다. 그래서 이 글에서는 간단하게나마 ISAPI를 Visual Studio 2005, 2008에서 개발하는 방법을 간단하게 정리한 글입니다. 여기서는 Visual Studio 2005에서 ISAPI Extension 개발에 대한 내용입니다.
1. 새로운 프로젝트 생성하기
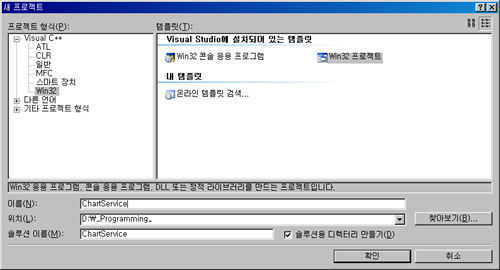
정확히 말해 ISAPI는 일반적인 DLL일 뿐입니다. 여기서 몇가지 함수를 외부로 Export 시켜 IIS가 이 함수를 호출함으로써 서로 통신을 하게됩니다. 그 몇가지 함수가 무엇인지는 아래에 설명하겠습니다.
2. 프로젝트 위저드 설정하기
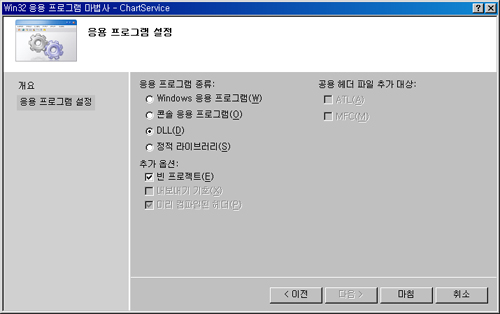 앞서 설명한 것처럼 응용프로그램 종류는 DLL로 지정하며 일단 빈 프로젝트로 생성합니다.
앞서 설명한 것처럼 응용프로그램 종류는 DLL로 지정하며 일단 빈 프로젝트로 생성합니다.
3. 모듈파일 추가하기
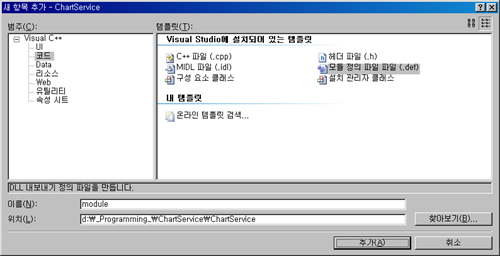 외부로 Export할 함수를 지정하기 위한 파일인 모듈파일을 추가합니다.
외부로 Export할 함수를 지정하기 위한 파일인 모듈파일을 추가합니다.
4. 모듈 파일이 Export할 함수명 지정하기
LIBRARY "ChartService"
EXPORTS
HttpExtensionProc
GetExtensionVersion
TerminateExtension앞서 추가한 모듈파일인 module.def에 3개의 함수를 Export 하는데, 위처럼 HttpExtensionProc, GetExtensionVersion, TerminateExtension 입니다. 각 함수의 역활은 아래서 간단하게 살펴보겠습니다.
5. Export할 함수를 구현할 파일 추가하기
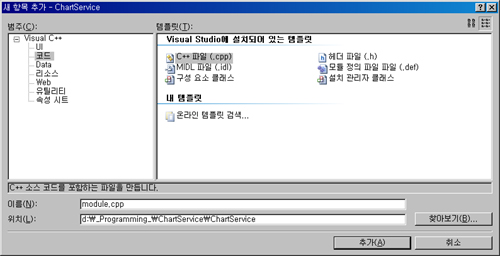 앞에서 언급한, 외부로 Export 할 함수를 구현할 cpp 파일 추가합니다.
앞에서 언급한, 외부로 Export 할 함수를 구현할 cpp 파일 추가합니다.
6. Export할 함수 구현하기
#include
#include
#include
BOOL WINAPI TerminateExtension(DWORD dwFlags)
{
// 실제 구현
return TRUE;
}
BOOL WINAPI GetExtensionVersion(HSE_VERSION_INFO *pVer)
{
// 실제 구현
return TRUE;
}
DWORD WINAPI HttpExtensionProc(EXTENSION_CONTROL_BLOCK *pecb)
{
// 실제 구현
return HSE_STATUS_SUCCESS;
}이미 이 글을 읽어볼 요량이셨다면, .. 아마도 .. ISAPI은 한번쯤 개발해보셨다고 생각이되는데요.. 여기서는 일단 이 함수들의 주요목적에 대해서만 간단하게 설명드리겠습니다.
TerminateExtension은 서비스가 IIS로부터 Unload될때 실행되는 함수이고, GetExtensionVersion은 서비스가 IIS로부터 처음 Load될때 실행되는 함수입니다. 그리고 HttpExtensionProc는 궁극적으로 클라이언트가 해당 서비스를 요청할때마다 실행되는 함수입니다. 이 상태에서 컴파일을 하면 하나의 dll이 만들어집니다. 실제로 이를 자신의 관리하고 있는 PC의 IIS에 배포을 해야하는데, 그 과정은 아래와 같습니다.
7. IIS에 배포하기
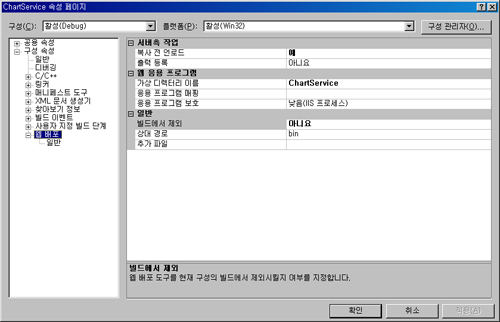 컴파일되어 생성된 dll을 IIS의 폴더에 복사하기전에 기존의 서비스를 Unload 시켜(복사 전 언로드를 예로 지정)야하고, 복사할 폴더의 이름을 지정하고(가상 디렉터리 이름을 지정) 빌드에서 제외를 ‘아니오’로 지정하면 됩니다.
컴파일되어 생성된 dll을 IIS의 폴더에 복사하기전에 기존의 서비스를 Unload 시켜(복사 전 언로드를 예로 지정)야하고, 복사할 폴더의 이름을 지정하고(가상 디렉터리 이름을 지정) 빌드에서 제외를 ‘아니오’로 지정하면 됩니다.