
이 글의 원문은 https://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_filtering/py_filtering.html#filtering 입니다.
OpenCV를 이용해 다양한 저주파 필터(Low-pass filter)를 이용해 이미지를 부드럽게, 즉 블러링(Bluring) 처리를 하는 내용입니다.
2D Convolution, 같은 의미로써 이미지 필터링(Filtering)은 고주파, 또는 저주파 필터를 이용해 이미지를 처리하는 것을 의미합니다. 여기서 필터는 예를들어 아래와 같은 행렬입니다.
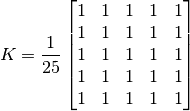
위의 필터가 이미지의 각 픽셀을 순회하면서 해당 픽셀 주위의 픽셀들와 곱해져 더해집니다. 위의 필터에 대한 이미지 필터링에 대한 예제 코드는 다음과 같습니다.
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('./data/opencv_logo.png')
kernel = np.ones((5,5), np.float32) / 25
dst = cv2.filter2D(img, -1, kernel)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(dst),plt.title('Averaging')
plt.xticks([]), plt.yticks([])
plt.show()
위의 7번 코드가 앞의 필터 행렬을 생성하고 있고 8번코드의 cv2.filter2D 함수가 이미지에 대해 해당 필터를 적용하여 그 결과 이미지를 반환합니다. 실행 결과는 다음과 같습니다.
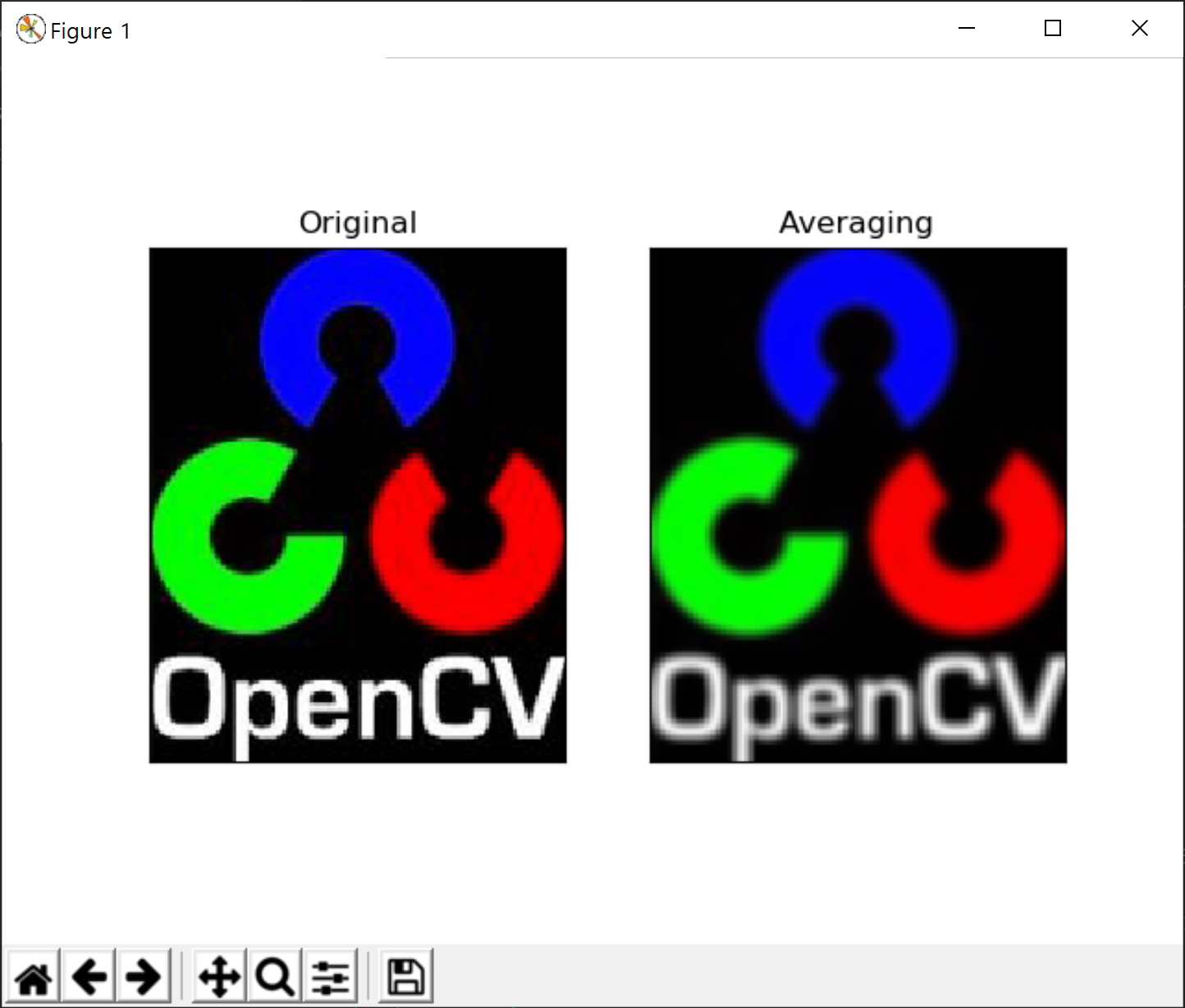
다시 이글의 주제로 돌아와서 이미지를 부드럽게 처리하는 LPF로써 OpenCV에서 제공하는 4가지 필터를 정리합니다. 먼저 평균 필터인데, 이는 이미 앞의 예제 코드와 동일하며 다음과 같은 코드 역시 동일한 결과를 생성합니다.
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('./data/opencv_logo.png')
blur = cv2.blur(img,(5,5))
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
다음은 가우시안 필터링(Gaussian Filtering)에 대한 예제입니다.
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('./data/opencv_logo.png')
blur = cv2.GaussianBlur(img,(5,5),0)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
다음은 Median Filtering에 대한 예제인데, 이 필터는 잡음 제거 효과가 뛰어납니다.
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('./data/opencv_logo.png')
blur = cv2.medianBlur(img,5)
#
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
다음은 Bilateral Filtering이며 잡음 제거 효과가 좋으면서, 가장자리를 보존하는데 효과적입니다. 단, 속도가 느리다는 단점이 있습니다.
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('./data/opencv_logo.png')
blur = cv2.bilateralFilter(img,9,75,75)
plt.subplot(121),plt.imshow(img),plt.title('Original')
plt.xticks([]), plt.yticks([])
plt.subplot(122),plt.imshow(blur),plt.title('Blurred')
plt.xticks([]), plt.yticks([])
plt.show()
